沉浸式翻译团队新品:BabelDOC PDF,无损翻译 PDF,免费用户可用
文章摘要
沉浸式翻译团队最近开源了其PDF翻译工具——BabelDOC PDF,该工具在很大程度上解决了PDF机翻中常见的排版乱码、串行等问题,能够直接输出对版的精准PDF。BabelDOC PDF发布后迅速冲进了Github全站全开发语言Trending榜的前三,并新增了多语种支持功能,支持使用拉丁字母的语言翻译成简体中文、繁体中文、日文和韩文,同时上线了中、日、韩三国文字之间的互译功能。免费用户每月可享1000页解析额度及GLM-4-FLASH翻译,Pro用户最多可享受每月10000页解析额度,并可以使用DeepSeek翻译模型。
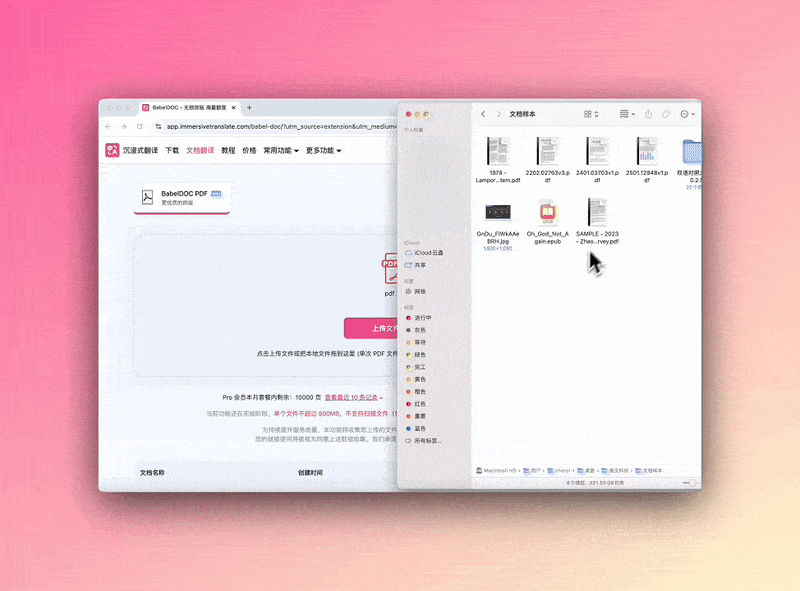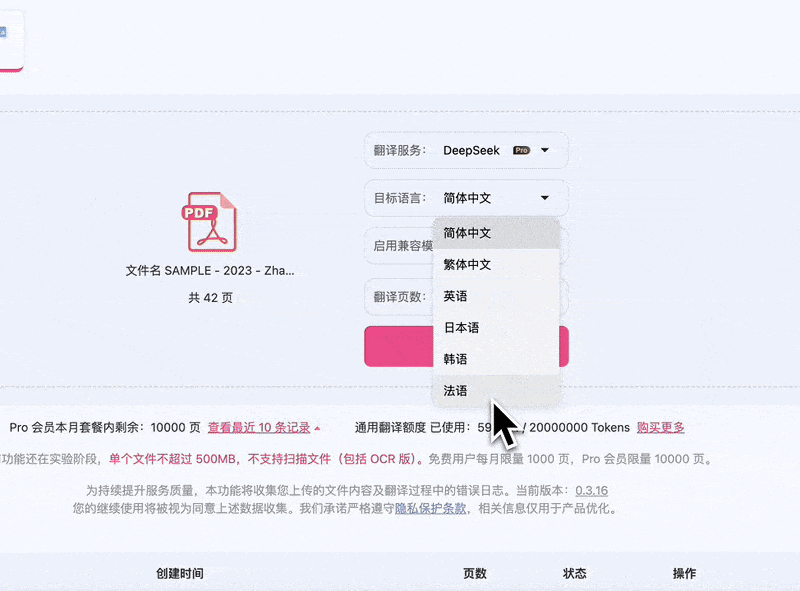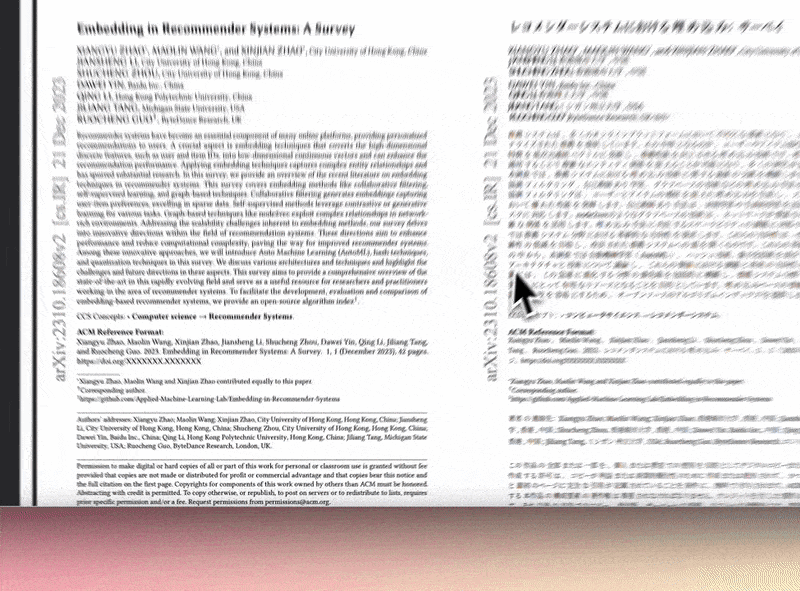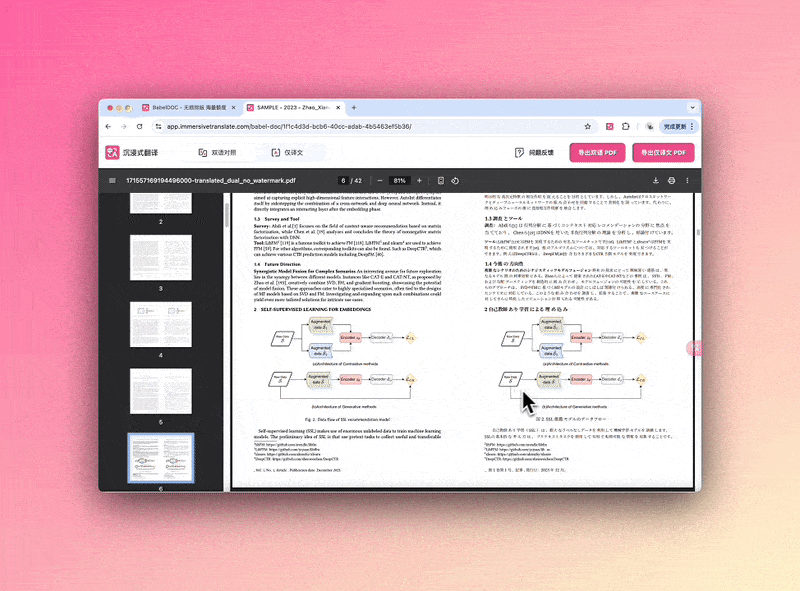
BabelDOC PDF通过AI布局识别技术,能够完整地提取并翻译PDF中的内嵌图表、脚注、公式等非文本元素,实现译文与源文件之间像素级版式对齐。该工具首先解析PDF的内容,包括文件头尾、图片、文字等元素,然后通过AI布局识别技术辨认文本的布局、段落结构及复杂的内容排版情况,如图片、表格和数学公式,并“记忆”下来。接着,提取文本并交给大语言模型进行翻译,翻译完成后,将翻译好的文字与识别的排版情况进行比对,智能匹配对应的字体、行距等样式,确保文本适应新的布局。对于图片和复杂公式,BabelDOC PDF会进行识别和解析,富文本的文字部分进行翻译,公式则以字符形式保留。最后,通过智能渲染的方式,将翻译好的文字调整大小尺寸,重新排版数学公式、图片、表格等,写入新文档,完成翻译和排版复原。
PDF翻译之所以复杂,源于PDF的文件结构。PDF文档由Adobe公司发明,旨在解决文档在不同设备上显示效果不一致的问题。PDF的文件结构如同一棵大树,根部是文件头尾,包含二进制代码和交叉引用表等资源的位置;末端枝干是页面树,记录图片、文字等元素的引用情况;主干分叉部分是交叉引用表,指示信息存放位置;叶子、花朵、果实是资源,包含字体、图像、颜色空间等细节;导管系统是内容流,记录PDF页面的绘制指令。打开PDF文档的过程复杂,涉及多个步骤,BabelDOC PDF通过解析这些结构,实现精准翻译和版式对版。
此外,Founder Park正在搭建「AI 产品市集」社群,邀请从业者、开发人员和创业者加入,提供最新AI新品资讯、热门新品邀请码、会员码及精准的AI产品曝光渠道。
原文和模型
【原文链接】 阅读原文 [ 1460字 | 6分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆


相关文章



