李飞飞团队统一动作与语言,新的多模态模型不仅超懂指令,还能读懂隐含情绪
文章摘要
【关 键 词】 多模态、语言模型、动作生成、预训练、泛化能力
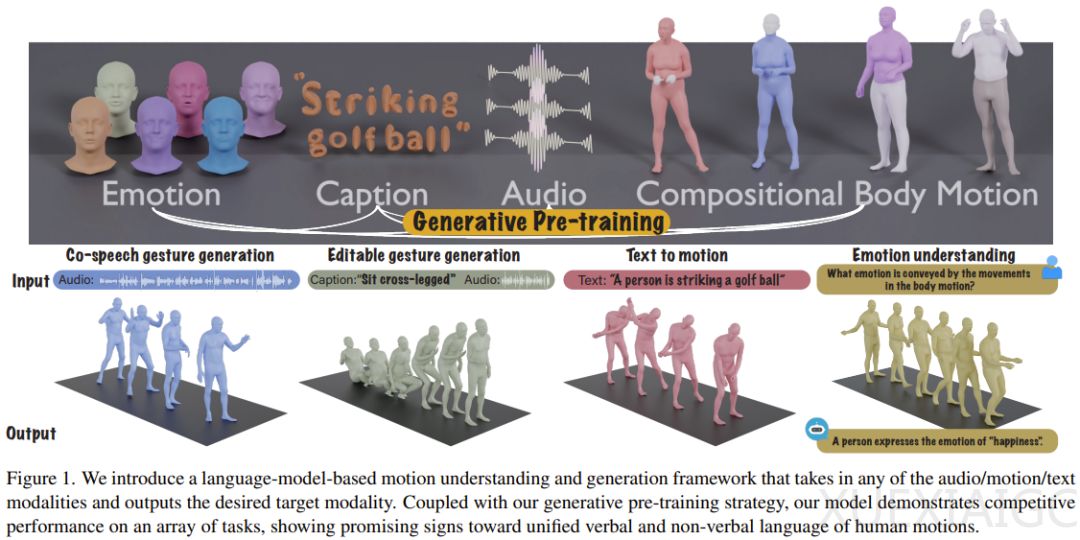
斯坦福大学的研究团队在多模态语言模型领域取得了新进展,提出了一种能够同时处理语音、文本和动作生成任务的模型。该模型能够理解并生成富有表现力的人类动作,通过音频和文本输入生成协调一致的动作,同时支持动作编辑功能,能够将指定的动作序列替换为其他动作,而不影响动作的自然流畅性和与语音内容的协调性。
研究团队强调了语言模型在统一人类动作的言语和非言语语言中的重要性,原因在于语言模型能够自然地与其他模态连接,富含语义的语音需要强大的语义推理能力,以及经过大量预训练的语言模型具备强大的语义理解能力。为此,他们设计了一种新的多模态语言模型,通过将动作token化,结合文本和语音token化策略,将任何模态的输入表示为token。
该模型的训练采用两阶段式流程:预训练阶段通过身体组合动作对齐与音频-文本对齐来对齐不同模态;预训练完成后,将下游任务编译成指令,并根据这些指令训练模型以遵循各种任务指令。实验结果表明,新方法得到的多模态语言模型在数据严重缺乏的情况下,预训练策略的优势更为明显,表现出了显著的泛化能力。
此外,该模型还展现出了在新任务上的出色能力,例如根据动作预测情绪,这表明其能够解读人的肢体语言。研究团队认为,这是首个构建多模态语言模型来统一3D人体动作的言语和非语言语言的工作,对于空间智能的研究具有重要意义,并在游戏和虚拟现实等应用领域具有潜在价值。
原文和模型
【原文链接】 阅读原文 [ 3414字 | 14分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...


