时隔6年,谷歌BERT终于有替代品了!更快更准更长,还不炒作GenAI
文章摘要
【关 键 词】 ModernBERT、AI模型、编码器、性能提升、注意力机制
新型AI研发实验室Answer.AI和英伟达等近日发布了ModernBERT,这是一个在速度和准确率上显著改进的模型系列,包含基础版139M和较大版395M两个型号。ModernBERT采用了近年来在大型语言模型(LLM)方面的数十项进展,包括对架构和训练过程的更新,其上下文长度增加到8k个token,而大多数编码器只有512个token,并且是第一个在训练数据中包含大量代码的仅编码器专用模型。
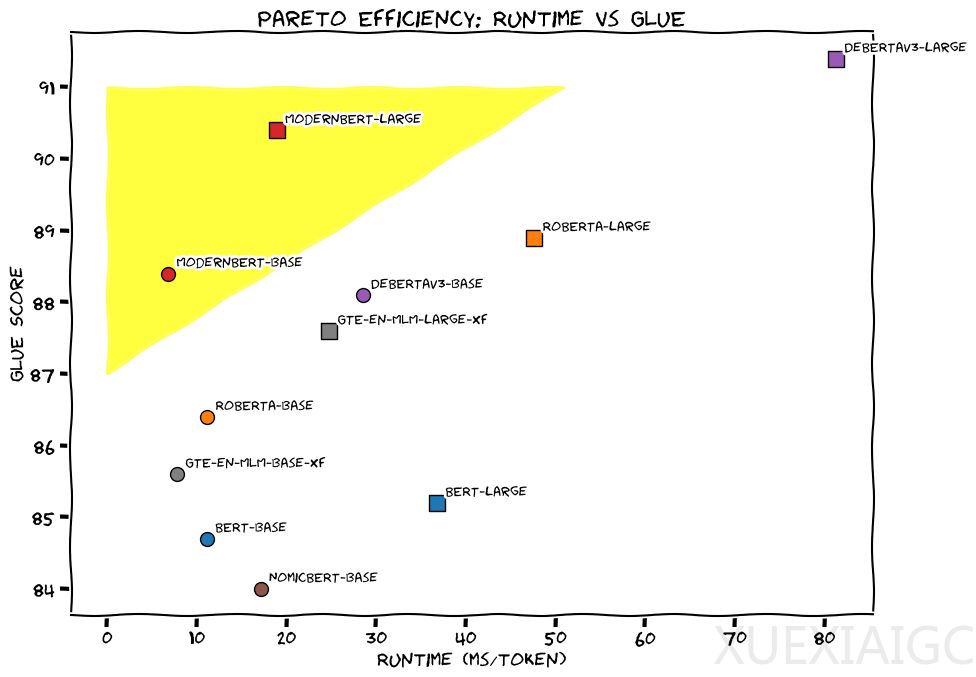
ModernBERT不炒作生成式AI(GenAI),而是真正的主力模型,可用于检索、分类等实际应用。与仅解码器模型相比,仅编码器模型的输出是数值列表(嵌入向量),将“答案”直接编码为压缩的数字形式,更适合许多科学和商业应用。ModernBERT在一系列任务中的准确率比较中是唯一在每个类别中都获得最高分的模型,其速度是DeBERTa的两倍,在输入混合长度的情况下,速度最高可提高4倍。ModernBERT的上下文长度为8,192个token,比大多数现有编码器长16倍以上。对于代码检索,ModernBERT的性能是独一无二的,因为之前从未有过编码器模型在大量代码数据上经过训练。
ModernBERT项目主要有三个核心点:现代化的transformer架构、特别重视注意力效率以及数据。ModernBERT采用了Alternating注意力机制,而不是全局注意力机制,可以更快地处理长输入序列。另一个有助于ModernBERT提高效率的核心机制是Unpadding和序列Packing,避免了模型在填充token上的计算浪费。ModernBERT的训练数据具有多种英语来源,包括网页文档、代码和科学文章,训练了2万亿tokens,其中大多数是唯一的。团队坚持原始BERT训练方法,并在后续工作的启发下进行了一些小的升级,包括删除了下一句(Next-Sentence)预测目标,并将掩蔽率从15%提高到30%。两个模型都采用三段式训练流程,首先在序列长度为1024的情况下训练了1.7T tokens的数据,然后采用一个长上下文适应阶段,在序列长度为8192的情况下训练了250B tokens的数据,最后按照ProLong中强调的长上下文扩展思路,对不同采样的50B tokens数据进行退火。总之,ModernBERT成为新的小型、高效的仅编码器SOTA系列模型,并为BERT提供了亟需的重做,证明了仅编码器模型可以通过现代方法得到改进,并在一些任务上仍能提供非常强大的性能,并实现极具吸引力的尺寸/性能比。
原文和模型
【原文链接】 阅读原文 [ 3634字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




