新PyTorch API:几行代码实现不同注意力变体,兼具FlashAttention性能和PyTorch灵活性
文章摘要
【关 键 词】 注意力机制、FlexAttention、PyTorch、机器学习、性能优化
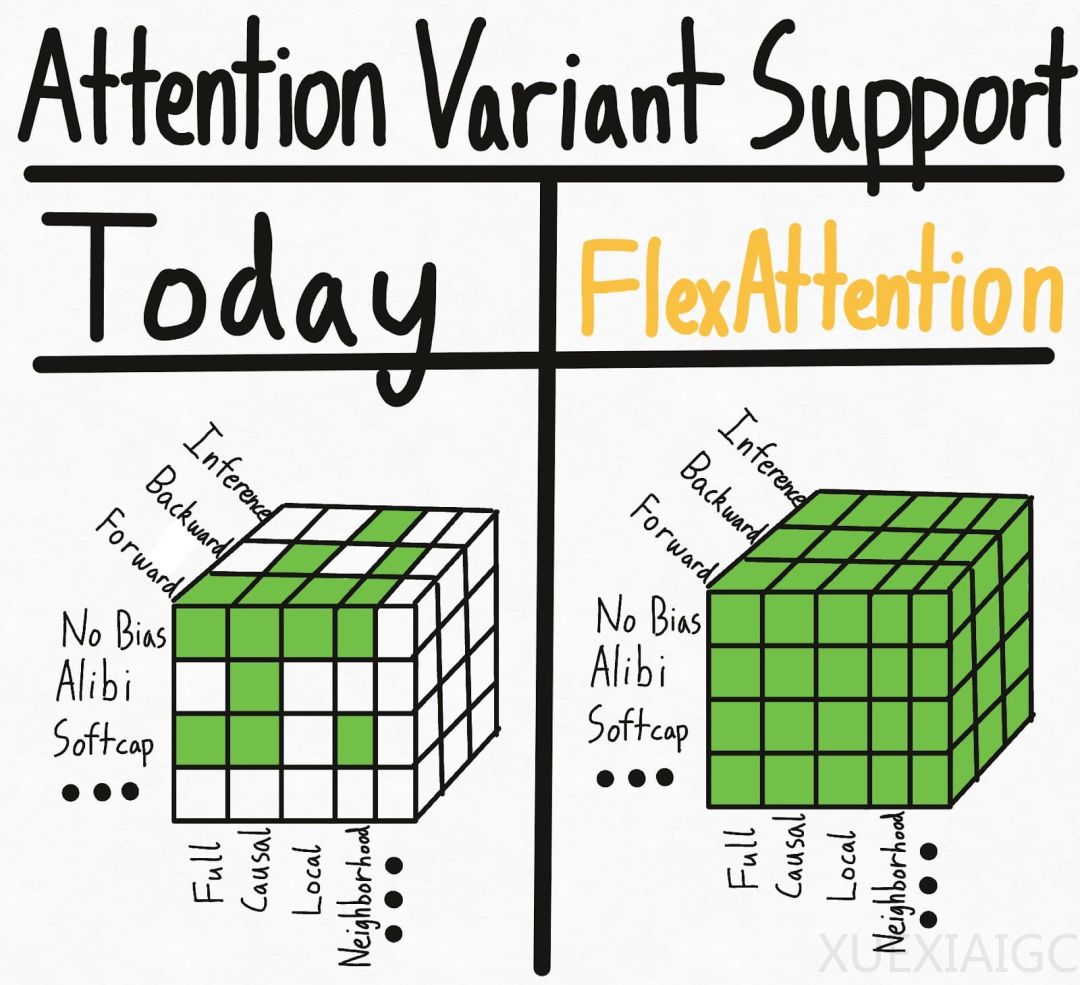
机器之心报道了PyTorch团队为解决注意力机制实现中的超立方体问题而引入的FlexAttention。注意力机制在机器学习中至关重要,但现有的实现如FlashAttention虽然性能高,却牺牲了灵活性。研究人员面临运行缓慢和CUDA内存不足的问题,尤其是当尝试组合多种注意力变体时。
为了应对这一挑战,PyTorch团队推出了FlexAttention,一个灵活的API,允许用户通过几行代码实现多种注意力变体。通过torch.compile,FlexAttention能够将代码降低到一个融合的FlashAttention内核中,生成性能与手写内核相媲美且不占用额外内存的内核。此外,FlexAttention利用PyTorch的自动求导机制自动生成反向传播,并利用注意力掩码中的稀疏性显著改善标准注意力实现。
FlexAttention的核心是一个用户定义的函数score_mod,它允许在softmax之前修改注意力分数,满足大多数用户对注意力变体的需求。例如,全注意力情况下,score_mod无操作,直接返回输入分数。相对位置编码则根据查询和键之间的距离调整分数,而不需要具体化SxS张量。Soft-capping技术和Causal Mask也在FlexAttention中得到应用。
FlexAttention还支持滑动窗口注意力和因果注意力的组合。研究者对带有滑动窗口掩码的F.scaled_dot_product_attention和带有因果掩码的FA2进行基准测试,结果表明FlexAttention在性能上明显优于这两种实现。
总体而言,FlexAttention的性能接近手写的Triton内核。虽然由于通用性会遭受轻微的性能损失,但前向传播实现了FlashAttention2性能的90%,在反向传播中实现了85%。研究者计划改进FlexAttention的反向算法,以缩小与FAv2的性能差距。
这项研究得到了FlashAttention 1-3版本的参与者Tri Dao的转发和评论,认为这项研究使得很多技术都融合在一起。FlexAttention的推出为机器学习研究人员提供了一个灵活、高效且易于实现的注意力机制解决方案,有望推动相关领域的进一步发展。
原文和模型
【原文链接】 阅读原文 [ 1176字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章


