斯坦福新作:无指令调优的指令遵循
文章摘要
【关 键 词】 指令调优、隐式适应、响应调优、单任务调优、NLP研究
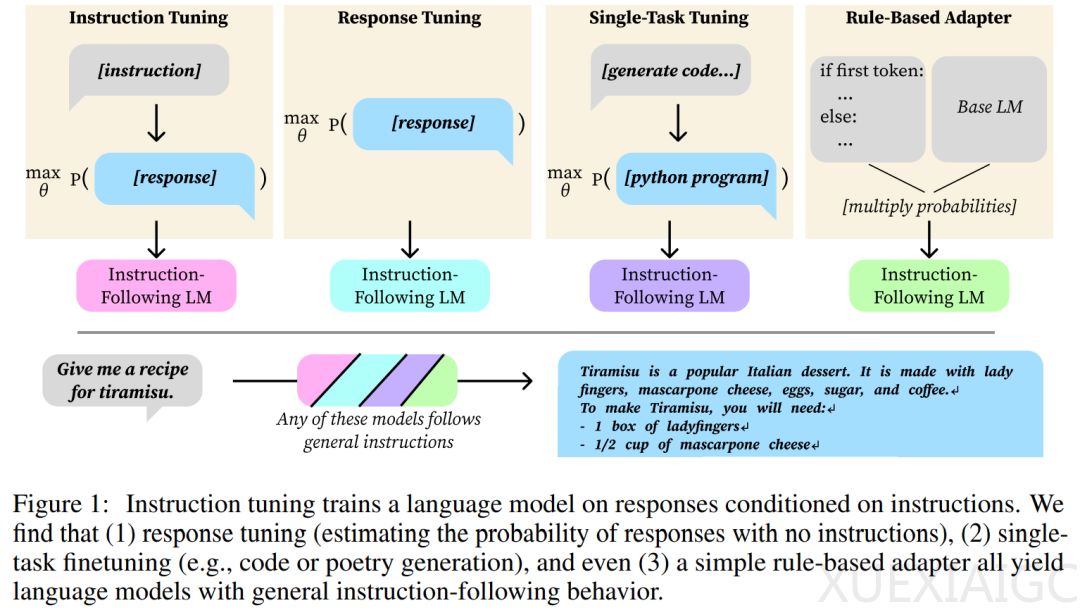
斯坦福大学的研究人员深入探讨了指令调优技术,该技术通过微调模型输入来适应特定任务。研究显示,即使不使用明确设计的指令调优方法,也能隐式地产生指令遵循行为。研究者发现了两种隐式指令调优的适应形式:响应调优和单任务调优。
响应调优仅对响应进行训练,不提供明确的指令到响应的映射信息,但提供了所需响应分布的信息。使用LIMA数据集进行调优后,在AlpacaEval 2上的评估显示,响应调优模型与指令调优模型相比,有43%的胜率。这表明指令-响应映射可以在预训练期间学习,尽管理想响应的概率可能太低而无法生成。
单任务调优则仅对来自狭窄目标领域的数据进行训练,如将英语请求映射到Python片段,或从诗歌标题生成诗歌。研究发现,即使训练只生成特定类型的输出,如Python代码或诗歌,模型在收到指令后仍能生成其他类型的输出,如传记或食谱。
实验设置包括指令调优、指令格式、定义指令遵循行为、AlpacaEval评估、贪婪解码等。研究者使用LIMA数据集和Llama-2-7B及OLMo-7B-Feb2024语言模型进行实验,发现响应调优模型的行为比基础模型更接近指令调优模型,尽管指令调优始终优于响应调优。
研究还提出了响应排序能力的概念,即正确响应的分配概率高于其他随机指令的预期响应。计算结果显示,预训练模型的响应排序能力与指令调优模型类似。
在单任务微调方面,研究者发现在每个单任务微调数据集上对Llama-2-7B和OLMo-7B-Feb2024进行微调都会导致一般的指令遵循行为,且指令调优模型的胜率明显更高。
论文作者之一John Hewitt表示这是他在斯坦福NLP的最后一篇论文,他即将加入哥伦比亚大学担任助理教授。研究结果表明,即使适应方法本意不在于产生指令遵循行为,它们也可能隐式地做到这一点。
原文和模型
【原文链接】 阅读原文 [ 1899字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★☆


相关文章



