文章摘要
【关 键 词】 AIGC、大语言模型、视频生成、技术创新、StreamingT2V
近年来,人工智能生成内容(AIGC)领域取得了显著进展,特别是在大语言模型(LLM)的发展和应用落地方面。微软 & OpenAI、百度文心一言、讯飞星火等大型机构都在推动这一技术的前进。在这个背景下,Picsart人工智能研究所、德克萨斯大学和SHI实验室的研究人员共同开发了StreamingT2V视频模型,这是一个能够通过文本直接生成长达数分钟的高质量视频的模型。
StreamingT2V模型在视频生成领域是一个重要的突破。传统的视频模型由于训练数据和算法的限制,最多只能生成10秒的视频。而Sora模型的出现,通过文本生成了最多1分钟的视频,将文生视频领域推向了新的高度。StreamingT2V则进一步扩展了视频的长度,能够生成动作连贯、无卡顿的长视频,尤其在高速运动的表现上非常出色。
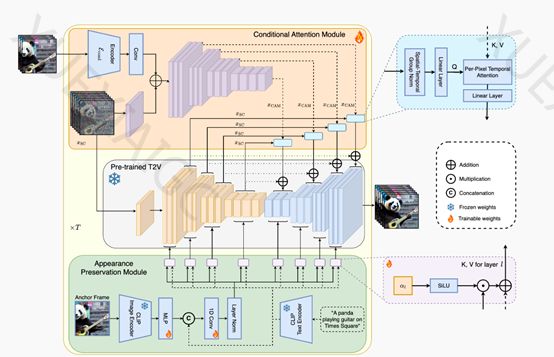
StreamingT2V模型采用了自回归技术框架,包括条件注意力、外观保持和随机混合三大核心模块。条件注意力模块通过注意力机制从前一个视频块中提取特征,并将其注入到当前视频块的生成中,实现流畅的块间过渡。外观保持模块则从初始图像中提取高级场景和对象特征,用于所有视频块的生成,保持了全局场景和外观的一致性。随机混合模块则通过自回归增强的方法,提高了视频的分辨率和质量。
这种自回归的方法类似于“击鼓传花”,每个模块都在提取前一个视频块的特征,以保证动作的一致性和视频的完整性。通过这种方法,StreamingT2V能够生成长达1分钟或2分钟的视频,而且视频中的物体运动姿态丰富,场景和物体随时间的演变更加自然流畅。
研究人员还表示,理论上StreamingT2V可以无限扩展视频的长度,并计划开源该视频模型,这将为AIGC开发者社区提供更多的可能性。开源地址已经提供,预示着未来将有更多的研究者和开发者能够利用这一模型进行创新和应用开发。
StreamingT2V模型的开发不仅是技术上的一大步,也为长视频模型的发展提供了新的思路。它的成功实验表明,未来我们可能会看到更多通过文本生成的长格式视频内容,这将极大地推动视频内容生产的自动化和个性化。随着技术的不断进步,StreamingT2V及其后续的改进版本有望在娱乐、教育、营销等多个领域发挥重要作用。
原文和模型
【原文链接】 阅读原文 [ 1319字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 gpt-4
【摘要评分】 ★★★☆☆


相关文章




