文章摘要
【关 键 词】 AI发展、数据危机、模型转变、合成数据、算法优化
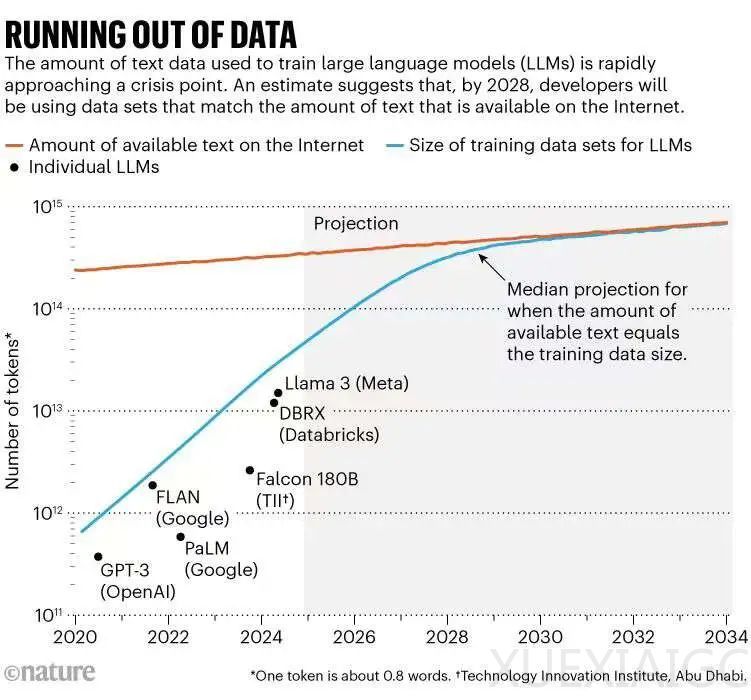
人工智能(AI)的发展在过去十年中取得了爆炸性的进展,这主要归功于神经网络规模的扩大和对大量数据的训练。然而,随着对数据的需求不断增长,AI研究人员正面临数据资源的枯竭问题。Epoch AI的研究人员预测,到2028年,用于训练AI模型的数据集规模将达到公共在线文本的总估计量,意味着AI可能在四年内耗尽训练数据。同时,数据所有者开始限制内容的使用,进一步加剧了数据共享的危机。
尽管存在这些限制,AI开发人员正在寻找解决方案。一些知名AI公司如OpenAI和Anthropic已经公开承认了这个问题,并表示他们有计划解决,包括生成新数据和寻找非常规数据源。数据危机可能会迫使AI模型从大型、通用的语言模型(LLM)转变为更小、更专业的模型。
过去十年中,LLM的发展显示出对数据的巨大需求。自2020年以来,用于训练LLM的“token”或单词部分的数量增加了100倍,从数千亿增至数万亿。然而,互联网上的内容增长速度远低于AI训练数据集的规模增长速度。内容提供商也在采取措施阻止网络爬虫或AI公司抓取其数据进行训练。
数据危机给传统AI的规模化策略带来了挑战。一种可能的解决方案是收集非公开数据,如WhatsApp的消息或YouTube视频的转录文字。另一种选择是专注于正在快速增长的专业数据集,如天文或基因组数据。此外,一些模型已经能够在一定程度上对未标记的视频或图像进行训练,扩展和改进这些能力可能会为更丰富的数据打开闸门。
如果找不到数据,可以多创造一些。一些AI公司付费让人为AI训练生成内容;另一些公司则使用AI生成的合成数据来训练AI。合成数据似乎适用于有严格、可识别规则的领域,如国际象棋、数学或计算机编码。然而,合成数据的问题在于,递归循环可能会巩固虚假信息,放大误解,并普遍降低学习质量。
另一种策略是放弃“越大越好”的概念,转而追求更高效、更专注于单个任务的小模型。这些模型需要精确、专业的数据和更好的训练技术。AI已经在用更少的资源做更多的事情,由于算法的改进,LLM实现相同性能所需的计算能力每八个月左右就会减半。
总体而言,专家们一致认为,合成数据、专门的数据集、重读和自我反思等因素都会有所帮助。模型能够独立思考,并且能够以各种方式与现实世界互动,这可能会推动AI的前沿发展。
原文和模型
【原文链接】 阅读原文 [ 3789字 | 16分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



