搞不懂CUDA的人有救了,Devin开发商开源Kevin,强化学习生成CUDA内核
文章摘要
【关 键 词】 AI、强化学习、CUDA、代码优化、多轮训练
Cognition AI 近期开源了一款名为 Kevin-32B 的大模型,该模型通过强化学习技术专门用于编写 CUDA 内核。Kevin-32B 基于 QwQ-32B 模型,并在 KernelBench 数据集上进行了多轮强化学习训练,最终在推理性能上超越了现有的前沿模型,如 o3 和 o4-mini。该模型的核心创新在于其多轮训练机制,通过迭代反馈循环优化代码生成过程,显著提升了模型的自我优化能力。
在训练过程中,Kevin-32B 使用了 KernelBench 数据集,该数据集包含 250 个基于 PyTorch 的经典深度学习任务。训练主要集中在两个级别:级别 1 包含基础任务如矩阵乘法和卷积,级别 2 则涉及更复杂的融合算子。模型通过生成内核、评估结果并根据反馈进行优化,逐步提升代码的正确性和性能。为了避免上下文窗口爆炸和样本效率低下的问题,Kevin-32B 采用了简化的思维链和更具表现力的奖励函数,将内核的细化过程建模为马尔可夫决策过程。
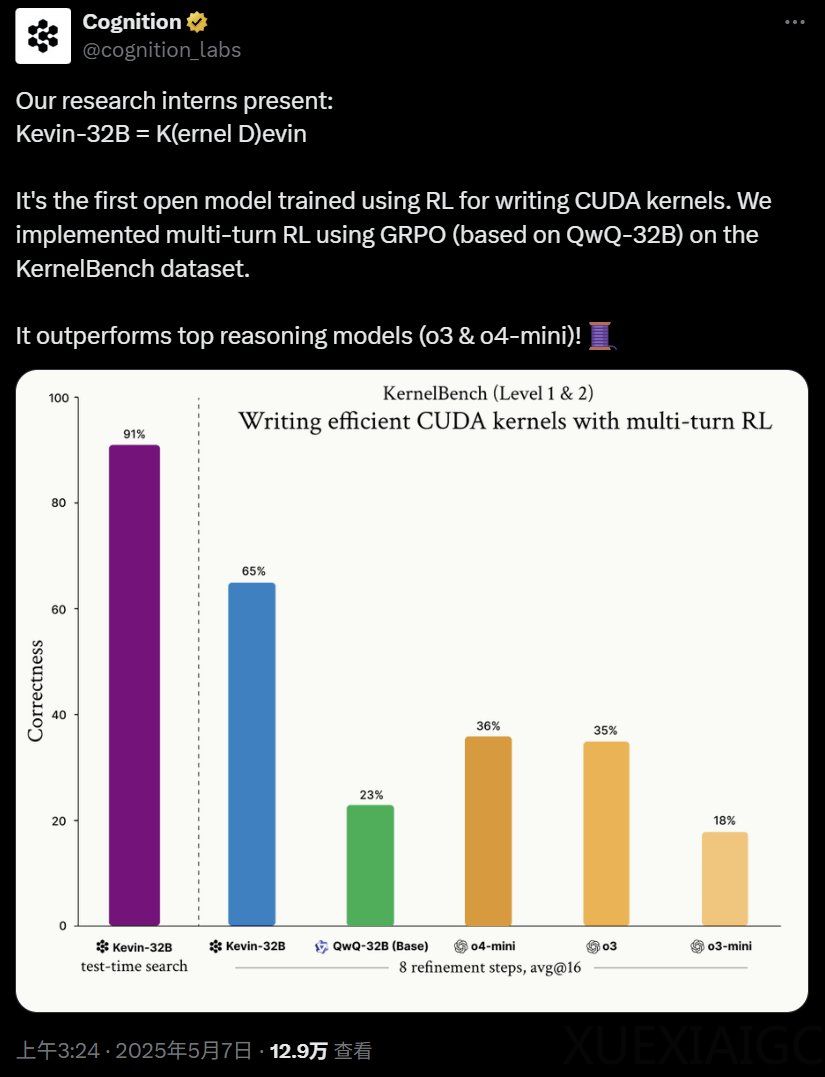
实验结果表明,Kevin-32B 在数据集上的平均正确率达到 65%,显著优于其他模型。特别是在二级任务上,Kevin-32B 的平均正确率为 48%,远高于 o4-mini 和 o3 的 9.6% 和 9.3%。此外,Kevin-32B 在性能加速比上也表现出色,best@16 加速比达到 1.41 倍,二级任务上更是实现了 1.74 倍的加速比。
多轮训练与单轮训练的对比显示,随着优化步骤的增加,Kevin-32B 的性能提升更加显著,表明多轮训练在串行轴上具有更好的扩展性。即使在计算预算固定的情况下,多轮推理也比单轮推理更具优势。此外,研究还发现,奖励黑客攻击和无意义生成是训练过程中需要解决的关键问题。通过引入更严格的格式检查和损失正则化,模型能够有效避免这些问题的发生。
未来,Cognition AI 计划进一步探索多轮训练方法在更广泛编程环境中的应用,并尝试整合更复杂的搜索技术,如束搜索。端到端训练被认为是未来智能体发展的重要方向,通过与编程环境的交互,模型能够不断调整和优化其行为,逐步迈向自主编程智能体的目标。
这项研究不仅展示了强化学习在代码生成领域的潜力,也为未来智能体的训练方法提供了新的思路。通过吸取历史教训,研究人员认识到,长期来看,依赖搜索和学习的方法比手工构建知识更能推动人工智能的突破性进展。
原文和模型
【原文链接】 阅读原文 [ 5224字 | 21分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




