提升生成式零样本学习能力,视觉增强动态语义原型方法入选CVPR 2024
模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 VADS、零样本学习、视觉增强、智能安防、多模态大模型
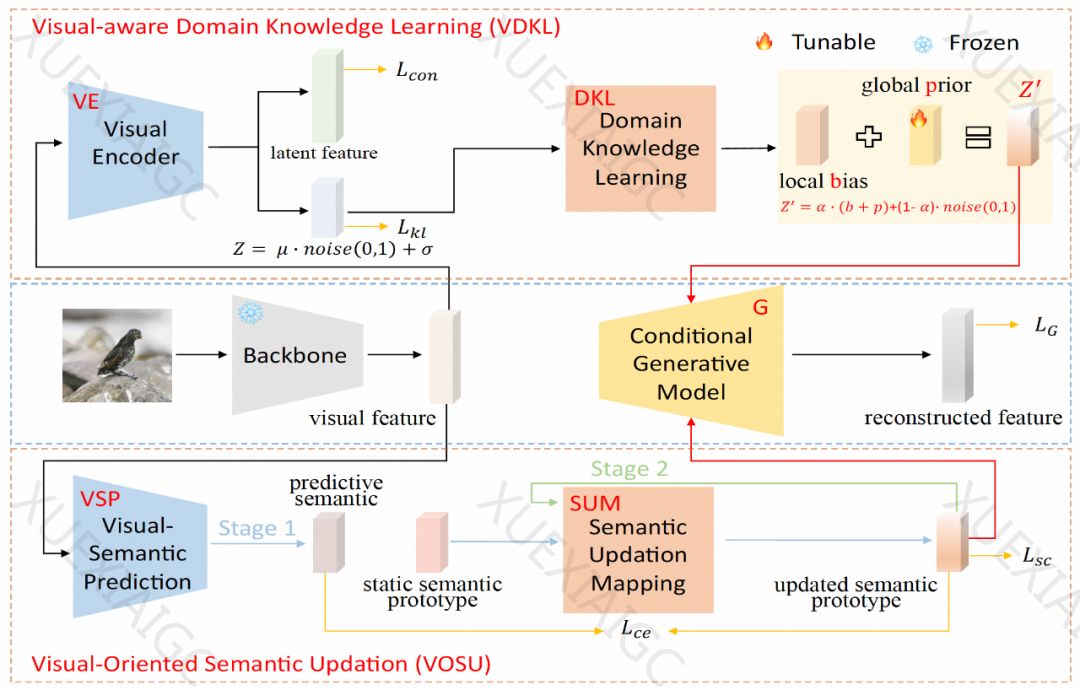
华中科技大学研究生与阿里巴巴旗下银泰商业集团的技术专家提出了一种名为视觉增强的动态语义原型方法(VADS),以提高生成式零样本学习(GZSL)的性能。VADS通过充分利用已见类的视觉特征,优化生成器的训练过程,从而提高模型的泛化能力和识别未见类的能力。研究论文已被计算机视觉顶级国际学术会议CVPR 2024接收。
VADS方法包含两个模块:视觉感知域知识学习模块(VDKL)和面向视觉的语义更新模块(VOSU)。VDKL模块通过视觉编码器和域知识学习网络学习视觉特征的局部偏差和全局先验,提供更丰富的先验噪声信息。VOSU模块则通过视觉语义预测器和语义更新映射网络,根据样本的视觉表示更新其语义原型。
实验结果表明,VADS方法在常用的零样本学习数据集上实现了显著的性能提升,并且可以与其他生成式零样本学习方法结合,获得精度的普遍提升。此外,VADS方法在智能安防领域具有潜在价值,有助于提高安全性、减少对样本数据的依赖以及提升动态环境下的稳定性。
研究者认为,生成式零样本学习的核心思想与当前多模态大模型中的视觉语言模型(如CLIP)的研究目标一致。尽管两者在应用范围和训练方式上有所不同,但在特定领域中,VADS方法可以为大模型的发展提供有益的启发。
原文信息
【原文链接】 阅读原文
【阅读预估】 2625 / 11分钟
【原文作者】 机器之心
【作者简介】 专业的人工智能媒体和产业服务平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...




