推荐大模型来了?OneRec论文解读:端到端训练如何同时吃掉效果与成本
文章摘要
【关 键 词】 推荐系统、生成式AI、端到端架构、算力优化、强化学习
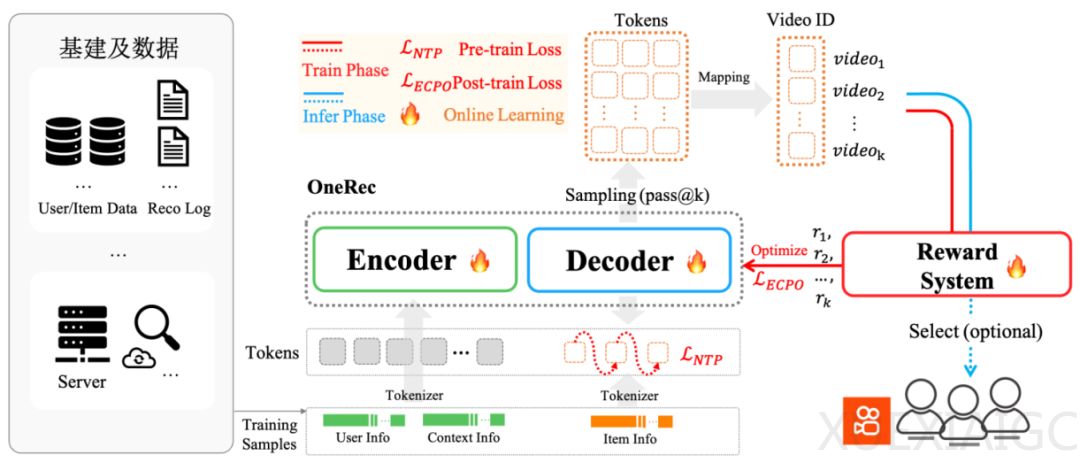
推荐系统正经历由大型语言模型(LLM)驱动的范式变革。传统级联架构因算力碎片化、目标冲突等问题面临瓶颈,而快手提出的端到端生成式系统OneRec通过整合Encoder-Decoder架构与MoE技术,实现了效果与效率的双重突破。该系统将推荐模型有效计算量提升10倍,训练/推理算力利用率(MFU)分别达到23.7%和28.8%,运营成本降至传统方案的10.6%,同时带动App停留时长提升0.54%-1.24%。
OneRec的核心创新体现在三方面。首先,采用多模态分词器和分层语义编码技术,将亿级视频内容转化为可理解的语义ID序列;其次,通过Encoder压缩用户终身行为数据,结合MoE解码器实现精准推荐生成;最后,引入强化学习奖励机制(如偏好奖励P-Score)突破传统推荐系统的性能天花板。实验显示,其参数规模扩展遵循Scaling Law规律,模型效果随参数增长持续提升。
在工程实现上,系统通过深度优化打破算力效率瓶颈。训练阶段采用SKAI系统实现GPU全流程Embedding训练,推理阶段通过计算复用、KV缓存等技术处理512并发生成请求。相比传统精排模型4.6%的MFU,OneRec的优化使GPU利用率提升3-5倍,算子数量减少92%至1200个。
线上AB测试验证了其跨场景适用性。除短视频场景外,本地生活服务场景GMV增长21.01%,新客获取效率提升23.02%。系统当前承载25%的QPS流量,但仍有三大待突破方向:推理能力扩展、多模态桥接技术完善,以及更精细的奖励系统设计。这项技术标志着推荐系统从传统管道模式向生成式架构的转型开端。
原文和模型
【原文链接】 阅读原文 [ 3822字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★☆☆


相关文章




