扩散LLM推理用上类GRPO强化学习!优于单独SFT,UCLA、Meta新框架d1开源
文章摘要
【关 键 词】 推理、扩散模型、强化学习、对数概率、性能提升
扩散模型在推理任务中的表现正逐渐受到关注,尤其是通过强化学习(RL)方法的应用。传统上,自回归大语言模型(LLM)在推理任务中占据主导地位,但离散扩散大语言模型(dLLM)作为一种非自回归替代方案,展现了独特的潜力。dLLM通过迭代去噪过程生成文本,利用双向注意力机制优化序列,并在多步骤操作中同时考虑过去和未来的上下文。尽管顶级开源dLLM尚未广泛采用RL后训练,但这一领域的研究空间巨大。
为了解决RL在非自回归模型中的应用难题,UCLA和Meta AI的研究者提出了一个两阶段后训练框架d1。该框架首先通过监督微调(SFT)在高质量推理轨迹上进行训练,随后引入了一种新颖的策略梯度方法diffu-GRPO,专门针对掩码dLLM设计。diffu-GRPO利用高效的一步对数概率估计,显著减少了RL训练所需的计算时间和在线生成数量。这一方法通过随机提示词掩码作为策略优化的正则化手段,进一步提升了训练效率。
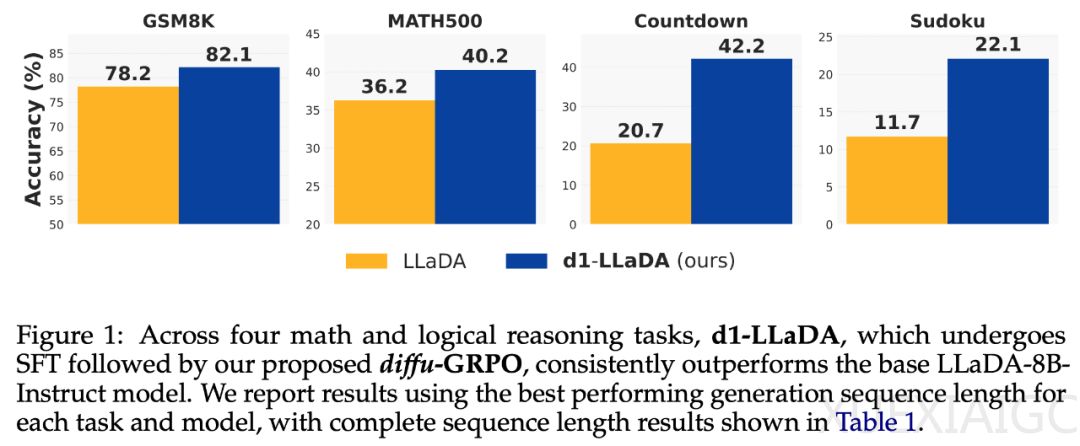
在实验中,研究者以LLaDA-8B-Instruct为基础模型,验证了d1框架的有效性。d1-LLaDA在四个数学和逻辑推理基准测试中均优于基础模型,并且在所有设置中都超过了仅使用SFT或diffu-GRPO的模型。这表明,结合SFT和diffu-GRPO的两阶段训练方案能够产生显著的性能提升,且两个阶段之间存在协同效应。
研究还发现,随着序列长度的增加,SFT和d1-LLaDA模型展现出自我修正机制和回溯行为,进一步提升了推理能力。这些定性结果表明,d1框架不仅在量化指标上表现优异,还在生成推理轨迹的质量上有所突破。总体而言,d1框架为扩散模型在推理任务中的应用提供了新的思路,并为未来的研究奠定了基础。
原文和模型
【原文链接】 阅读原文 [ 1743字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




