扩散模型训练方法一直错了!谢赛宁:Representation matters
文章摘要
【关 键 词】 REPA技术、扩散模型、表征对齐、视觉数据、训练效率
纽约大学的研究者谢赛宁及其团队提出了一种名为REPresentation Alignment(REPA)的表征对齐技术,旨在简化训练扩散Transformer的过程。该技术通过将预训练自监督视觉表征蒸馏到扩散Transformer中,提升了模型训练的效率和效果。Yann LeCun对此研究表示认可,认为即使在生成像素时,也应包含特征预测损失,以便解码器的内部表征能预测特征。
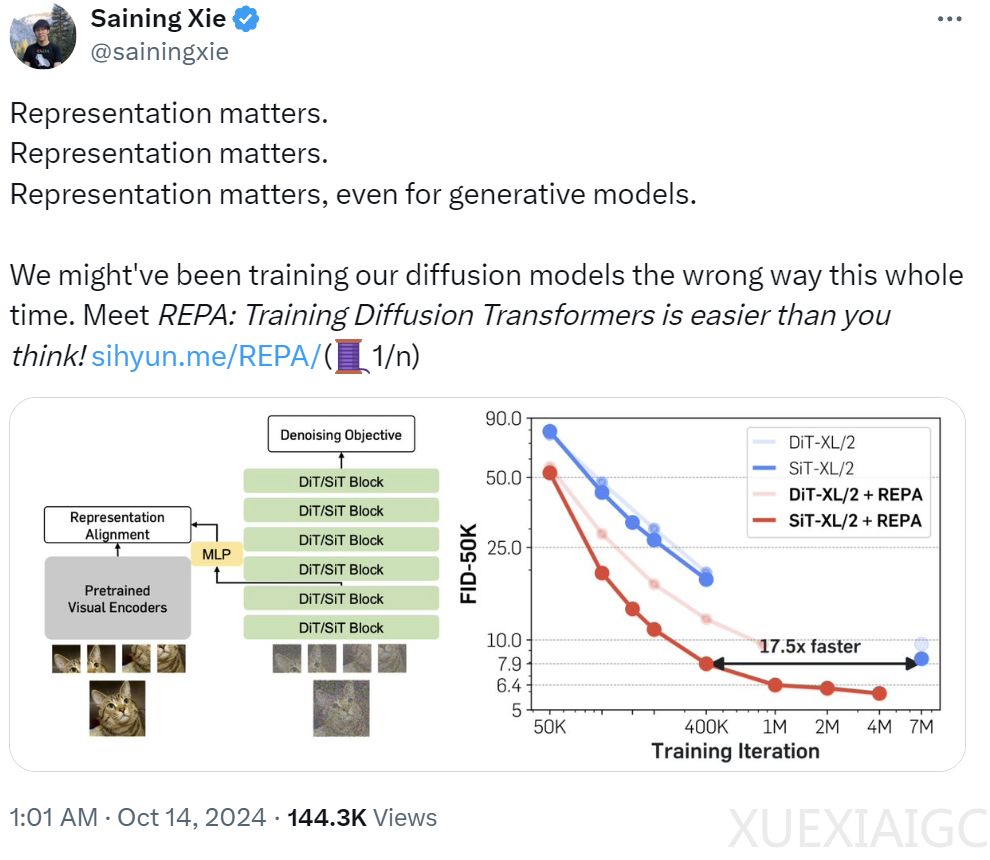
研究团队发现,训练扩散模型的主要挑战在于学习高质量的内部表征。他们通过对比扩散Transformer和监督式DINOv2模型的表征差距,发现两者之间存在显著的语义差距。REPA技术通过最大化预训练表征和隐藏状态之间的相似性,实现了模型隐藏状态与预训练自监督视觉表征的对齐。
REPA技术在实践中表现出色,能显著提升模型的收敛速度和生成质量。在没有无分类器引导的情况下,REPA在400K次迭代时实现了FID=7.9,优于普通模型在700万次迭代时的性能。使用无分类器引导时,带有REPA的SiT-XL/2的性能优于最新的扩散模型,迭代次数减少为1/7,并通过额外的引导调度实现了SOTA FID=1.42。
此外,REPA技术在大型模型中提供了更显著的加速效果,与普通模型相比,实现了更快的FID-50K改进。增加模型大小可以在生成和线性评估方面带来更快的增益。该研究还通过消融研究,探索了不同时间步数、不同视觉编码器和不同λ值(正则化系数)的影响。
总的来说,REPA技术通过表征对齐,显著提高了扩散Transformer的训练效率和生成质量,为生成高维视觉数据提供了一种有效的解决方案。这一研究为未来扩散模型的训练和应用提供了新的视角和方法。
原文和模型
【原文链接】 阅读原文 [ 2501字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




