文章摘要
【关 键 词】 蒸馏技术、推理模型、成本低廉、样本效率、预算强制
通过蒸馏技术,研究团队成功训练出一个性能可媲美DeepSeek-R1和OpenAI o1的推理模型s1,其成本不到150元人民币。这一成果由李飞飞、斯坦福大学、华盛顿大学及艾伦人工智能实验室共同完成,并在数学和编程能力评测中表现出色。
研究团队使用了仅16个英伟达H100 GPU,在26分钟内完成了模型训练,计算资源租赁成本约20美元。其核心方法是基于阿里通义Qwen2.5-32B-Instruct模型,通过蒸馏谷歌DeepMind的Gemini 2.0 Flash Thinking实验版进行训练。为支持训练,团队创建了一个名为s1K的数据集,包含1000个经过严格筛选的问题及其答案和推理过程。
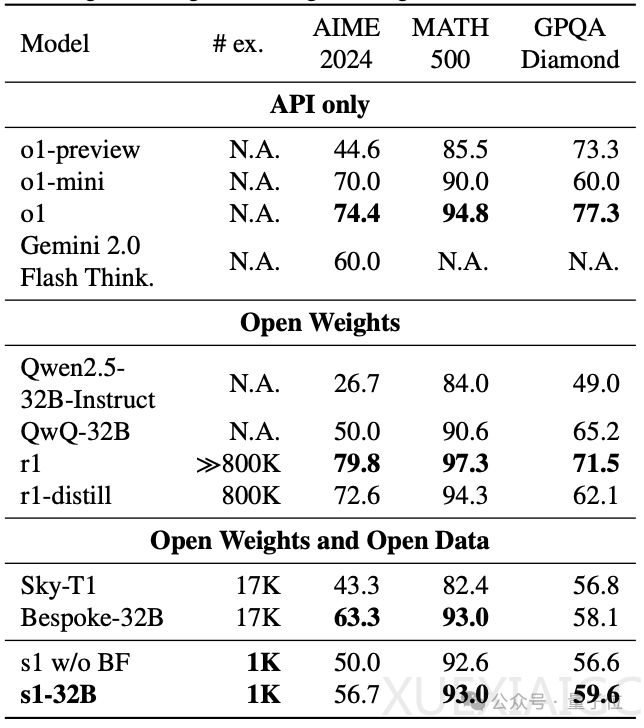
研究主要关注Test-time Scaling中的顺序Scaling方法,提出了一种简单但有效的干预手段——budget forcing,用以控制模型在推理阶段的思考时间长度。通过对生成的思考token数量设定上下限,团队使模型能够在适当的时间结束或延展推理过程。实验表明,这种方法显著提升了模型性能。例如,s1在MATH500测试中取得了93.0的成绩,与o1和DeepSeek-R1相当,并在AIME24测试中相较于o1-preview最高提升27%。
然而,研究也揭示了一些限制:过于频繁地抑制思考结束标记可能导致模型进入重复循环,阻碍进一步推理。此外,团队发现顺序Scaling优于并行Scaling,验证了其假设。值得注意的是,尽管仅使用1000个样本进行训练,s1-32B展现出极高的样本效率,被描述为“样本效率最高的开源数据推理模型”。
这项研究展示了蒸馏技术在低资源条件下实现高性能模型的潜力,同时突出了预算强制干预方法的有效性。未来,这一方向的研究有望进一步推动推理模型的技术进步,开启大模型领域更多创新可能。相关论文已发布在arXiv,代码与数据集开源在GitHub上供学术与行业参考。
原文和模型
【原文链接】 阅读原文 [ 1817字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 qwen-max-2025-01-25
【摘要评分】 ★★★★☆


相关文章




