文章摘要
【关 键 词】 rStar2模型、推理表现、技术突破、训练优化、智能体学习
微软研究院开源了AI Agent推理模型rStar2 – Agent,它在多个方面表现出色且实现了技术突破。
模型表现优异:rStar2 – Agent仅140亿参数,在AIME24数学推理测试中准确率达80.6%,超过6710亿参数的DeepSeek – R1的79.8%。在GPQA – Diamond科学推理基准测试和BFCL v3智能体工具使用任务中,其准确率和任务完成率也超过了DeepSeek – V3,展现出强大泛化能力。
解决推理难题:OpenAI的O系列等领先模型通过延长推理链提升性能,但面对难题存在局限性,依赖内部自我反思纠错效果不佳。微软转向智能体强化学习,让模型与工具环境交互并根据反馈调整推理过程,且实现了三大技术突破。
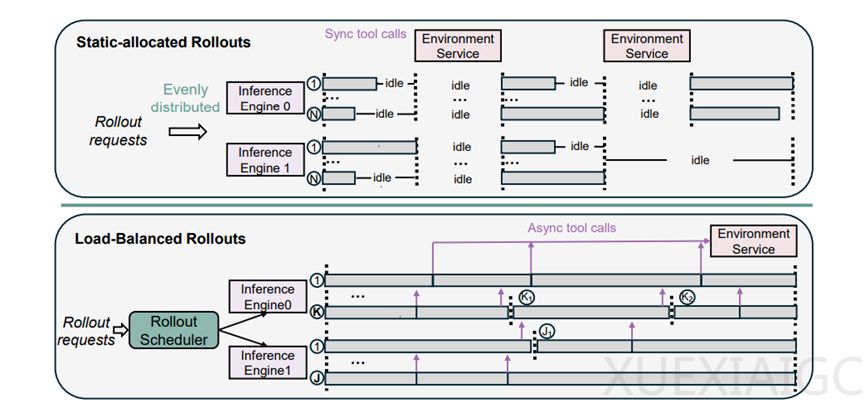
训练基础突破:传统本地Python解释器在大规模训练时效率低且有安全问题。微软打造的全新基础设施,其隔离式高吞吐代码执行服务部署在强大硬件基地,采用分布式架构。主节点负责接收和分配任务,工作节点实现负载均衡,能稳定支撑高并发工具调用,平均执行延迟仅0.3秒。动态负载均衡滚出调度器实时监控GPU缓存容量,动态分配任务,将GPU空闲时间降低60%以上,单批次滚出效率提升45%。
算法突破:环境噪声和传统奖励机制影响智能体强化学习。微软在GRPO算法基础上提出GRPO – RoC算法,对GRPO进行三项关键调整,移除KL散度惩罚项、采用Clip – Higher策略、取消熵损失项。RoC采用不对称采样机制,筛选解答尝试,使正奖励轨迹中工具错误率降至5%以下,推理响应长度缩短30%。
训练流程突破:大模型强化学习算力成本高,rStar2 – Agent设计了“非推理微调 + 多阶段强化学习”的训练流程。非推理微调阶段培养模型基础能力,提升工具调用准确率和指令遵循达标率。多阶段强化学习分三个阶段,逐步提升训练难度,仅用64台MI300X GPU在1周内完成510步强化学习迭代就达到性能峰值,降低了算力成本。
原文和模型
【原文链接】 阅读原文 [ 2479字 | 10分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★★


相关文章



