文章摘要
微软近日开源了Phi-4家族的最新版本Phi-4-mini-flash-reasoning,该版本延续了Phi-4家族参数小、性能强的特点,专门为受算力、内存和延迟限制的场景设计,适合在笔记本、平板电脑等边缘设备上运行。与前一个版本相比,mini-flash采用了微软自研的创新架构SambaY,推理效率提升了10倍,延迟平均降低了2—3倍,整体推理性能实现了显著提升。这一版本尤其适合教育、科研领域,特别是在高级数学推理能力方面表现出色。
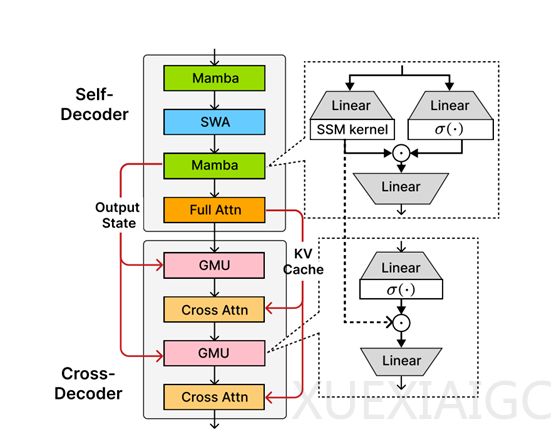
SambaY架构是微软与斯坦福大学联合研发的创新解码器混合架构,其核心在于通过引入门控存储单元(GMU)实现跨层的高效记忆共享,从而提升解码效率并保持线性预填充时间复杂度。GMU的设计灵感来源于门控线性单元、门控注意力单元和SSMs中的门控机制,通过可学习的投影和门控机制生成输出,使得当前层输入能够基于每个记忆通道的查询上下文,对前一层的标记混合进行动态的细粒度重新校准。在模型方面,SambaY的自解码器包含交错的Mamba层、滑动窗口注意力、SSM内核及线性层等组件,确保了预填充阶段的线性计算复杂度。
在解码阶段,SambaY架构将一半交叉注意力层的内存I/O复杂度从线性的O(dkv·N)降至常数O(dh),显著提升了效率。此外,SambaY在训练中采用了LeCun均匀初始化、RMSNorm等技术,进一步提升了训练稳定性。其增强变体SambaY+DA通过引入Differential Attention进一步提升了推理效率。
为了验证SambaY架构的性能,微软进行了广泛的测试,包括长文本生成、推理任务以及长上下文检索能力。在长文本生成任务中,SambaY在处理2K长度的提示和32K长度的生成任务时,解码吞吐量比传统的Phi4-mini-Reasoning模型提高了10倍。在高级数学推理任务中,SambaY在Math500、AIME24/25和GPQA Diamond等测试中表现优异,尤其是在AIME24/25任务中,能够准确解决复杂数学问题并生成清晰的解题步骤。
在长上下文检索任务中,SambaY在Phonebook和RULER等主流基准测试中表现突出。在Phonebook任务中,SambaY在32K长度的上下文中取得了78.13%的准确率,明显优于其他模型。在RULER任务中,即使滑动窗口较小,SambaY仍能保持较高的检索准确率。
为了进一步验证SambaY的可扩展性,微软进行了大规模预训练实验,使用了3.8B参数的Phi4-mini-Flash模型,并在5T tokens的数据集上进行了预训练。尽管在训练过程中遇到了一些挑战,如损失发散等,但通过引入标签平滑和注意力dropout等技术,模型最终成功收敛,并在MMLU、MBPP等知识密集型任务中取得了显著的性能提升。
原文和模型
【原文链接】 阅读原文 [ 1317字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




