强化学习让大模型自动纠错,数学、编程性能暴涨,DeepMind新作
文章摘要
【关 键 词】 自我纠正、强化学习、多轮训练、鲁棒性、DeepMind
在大语言模型(LLM)的研究领域,自我纠正能力一直是一个重要的研究方向。然而,现有的自我纠正训练方法通常依赖于多个模型或额外的监督,这限制了其实用性。Google DeepMind 的研究者在最近的一项研究中提出了一种新的自我纠正方法,即通过强化学习进行自我纠正(SCoRe),这种方法不需要外部反馈或额外模型,只需训练一个模型即可实现自我纠正。
SCoRe 方法的核心是通过多轮强化学习来训练模型,使其能够在自生成数据上进行自我纠正。这种方法分为两个阶段:第一阶段是训练模型初始化以防止崩溃,第二阶段是带有奖励的多轮强化学习。在第一阶段,研究者通过微调基础模型,使其在第二次尝试时产生高奖励修正,同时限制第一次尝试的响应分布,以避免崩溃现象。在第二阶段,模型在耦合两个响应时表现出更小的偏差,可以训练两次尝试的响应,并根据优化奖励进行调整。
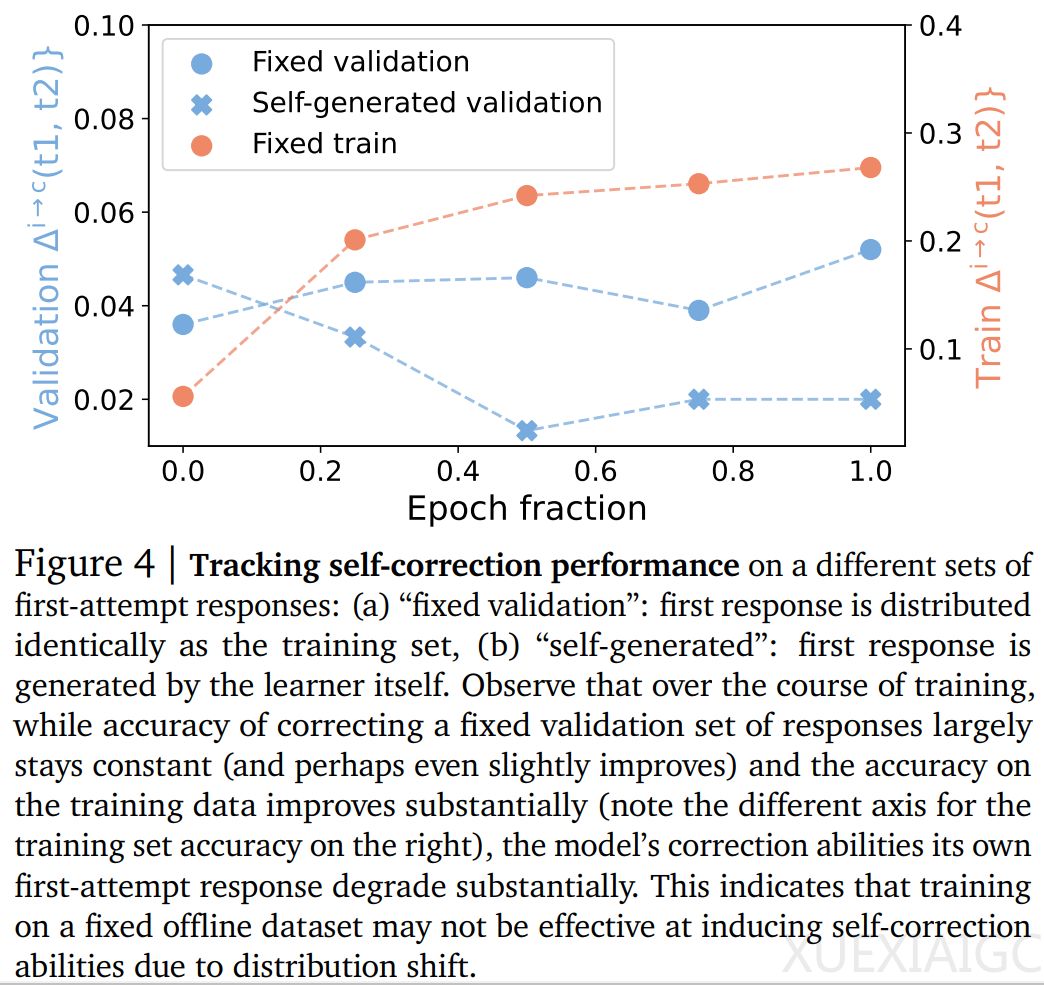
实验评估表明,SCoRe 方法在数学(MATH)推理问题和编码问题(HumanEval)上分别取得了15.6%和9.1%的增益,显示出其在自我纠正能力方面的有效性。此外,研究还通过消融实验探索了SCoRe的每个组件的影响,包括多轮训练的重要性、多阶段训练的重要性、奖励函数设计的影响以及on-policy强化学习的重要性。
这项研究的主要贡献在于提出了一种新的自我纠正方法,该方法不依赖于外部反馈或额外模型,而是通过强化学习在自生成数据上进行训练,从而提高了LLM的自我纠正能力。这对于提高LLM的鲁棒性和可靠性具有重要意义,也为未来的研究提供了新的思路和方法。
原文和模型
【原文链接】 阅读原文 [ 1619字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


