强化学习带来的改进只是「噪音」?最新研究预警:冷静看待推理模型的进展
文章摘要
【关 键 词】 推理、强化学习、模型评估、基准测试、性能提升
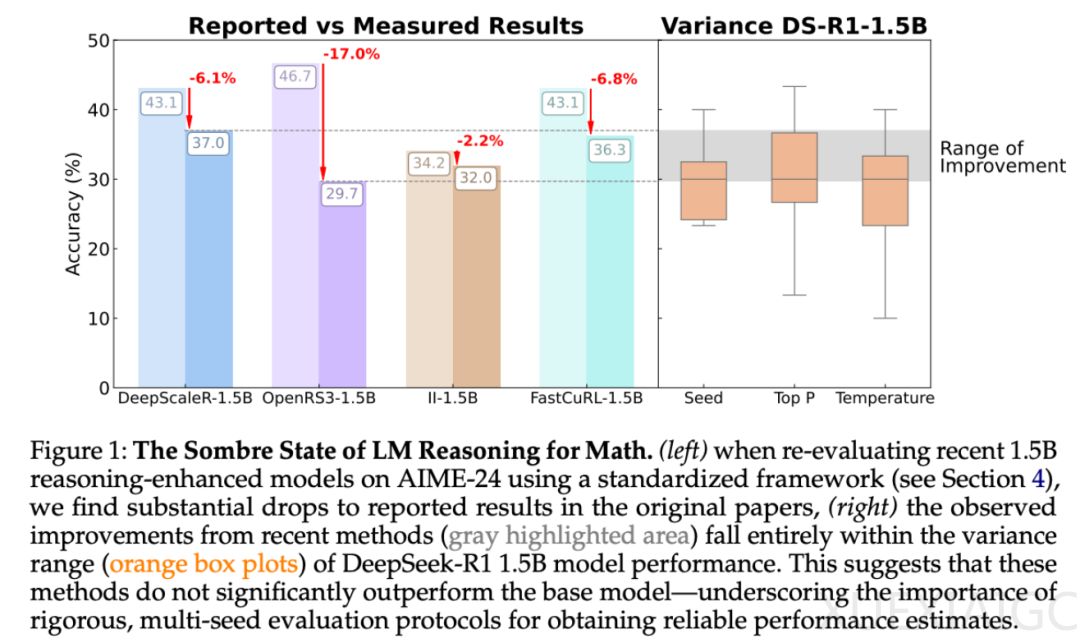
「推理」已成为语言模型的下一个主要前沿领域,学术界和工业界在探索模型推理性能提升的过程中,提出了一个核心问题:什么方法有效,什么方法无效?近期研究表明,强化学习(RL)在提升蒸馏模型的推理性能方面具有显著效果。然而,来自图宾根大学和剑桥大学的研究者指出,强化学习带来的许多「改进」可能只是噪音,尤其是在小型基准测试中,结果极不稳定,仅改变一个随机种子就可能导致得分发生几个百分点的变化。
研究者在数学推理领域广泛使用的测试平台 HuggingFaceH4 和 AI-MO 上进行了严格的调查,发现在更可控和标准化的设置下,强化学习模型的收益比最初报告的要小得多,且通常不具有统计显著性。尽管一些使用强化学习训练的模型表现出了适度的改进,但这些改进通常比监督微调(SFT)所取得的成果更弱,且不能很好地推广到新的基准。研究者系统分析了造成这种不稳定性的根本原因,包括采样差异、解码配置、评估框架和硬件异质性,并提出了一套最佳实践,旨在提高推理基准的可重复性和严谨性。
硬件和软件因素对模型性能的影响也被揭示。研究者在五个不同的计算集群上对同一模型进行了评估,发现硬件差异可能导致性能差异高达 8%。此外,不同 Python 框架下的评估结果也存在微小但显著的差异。研究还表明,提示格式和上下文长度对模型准确性有显著影响,使用数学特定提示和本地聊天模板时,模型表现最佳。
在标准化评估环境中,研究者对六个数学推理基准测试进行了模型评估,发现通过强化学习训练的方法未能显著提升性能,而监督微调(SFT)模型则表现出更强的泛化能力和韧性。研究还发现,较长的响应与较高的错误概率相关联,响应长度可以作为识别低置信度或失败生成的实用启发式思路。此外,准解码策略足以捕捉模型在有效推理路径上的完整分布,反驳了多样性坍缩假说。
研究进一步验证了响应长度与性能之间的关系,发现较短的响应更可能是正确的,而较长的响应则逐渐表现出更高的错误率。这一趋势在 RL 和 SFT 训练的模型中均存在,但在 RL 训练模型中更为显著。此外,研究并未观察到一致的多样性坍缩现象,Pass@1 的提升通常伴随着 Pass@k 的整体改善,尽管不同指标的提升幅度存在差异。
总体而言,研究强调了在模型评估中标准化和严谨性的重要性,并指出当前基于强化学习的方法容易过拟合,需要更严格的异域基准测试。相比之下,监督微调(SFT)模型表现出更强的泛化能力和韧性,突显了其作为训练范式的稳健性和成熟性。
原文和模型
【原文链接】 阅读原文 [ 2922字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




