强化学习也涌现?自监督RL扩展到1000层网络,机器人任务提升50倍
文章摘要
【关 键 词】 强化学习、神经网络、自监督、深度扩展、机器人
普林斯顿大学与华沙理工的研究表明,将对比强化学习(CRL)扩展到1000层可以显著提升性能,在某些机器人任务中性能提升高达50倍。这一发现挑战了传统观点,即强化学习任务通常仅使用浅层网络(2-5层),而深层网络在视觉和语言等领域更为常见。研究团队通过融合自监督学习和强化学习,提出了一种新的自监督强化学习系统,并采用对比强化学习算法。此外,研究还通过增加数据量和网络深度,结合残差连接、层归一化和Swish激活函数等技术,稳定了训练过程。
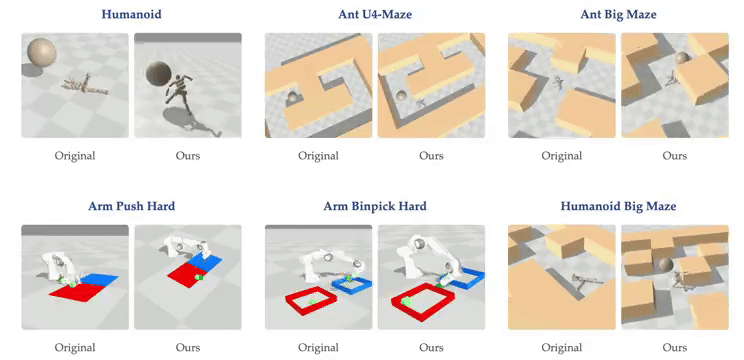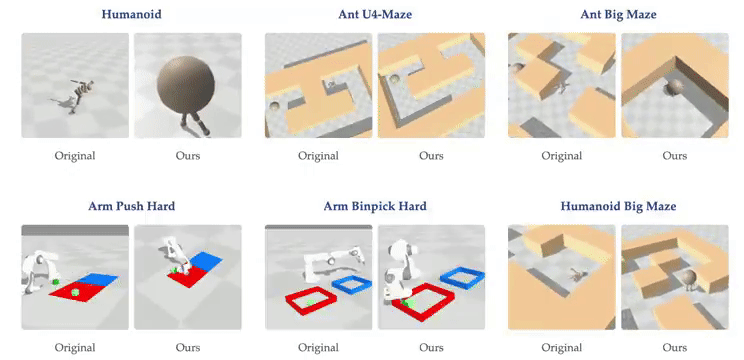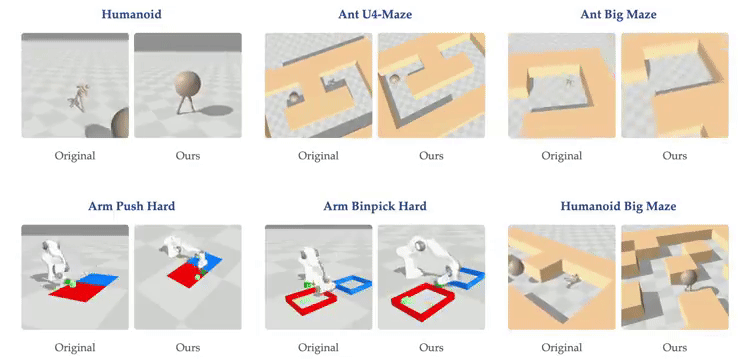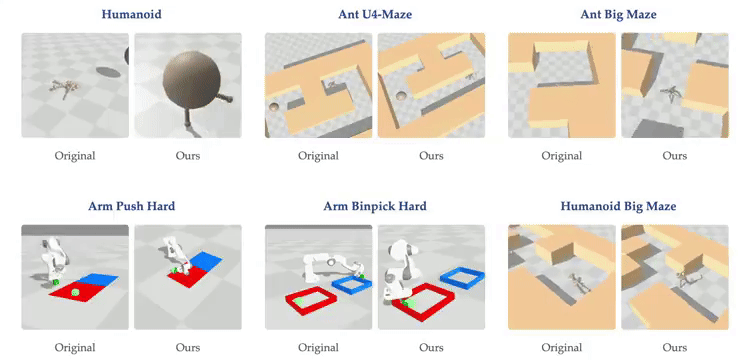
随着网络深度的增加,智能体在虚拟环境中表现出新的行为。例如,在深度4时,人形机器人会直接向目标坠落,而在深度16时,它学会了直立行走。在深度256时,智能体在U-Maze环境中学会了越过迷宫高墙。研究表明,在具有高维输入的复杂任务中,深度扩展的优势更为显著。在Humanoid U-Maze环境中,研究人员测试了扩展的极限,发现性能在1024层时仍持续提升。
更深的网络能够学习到更好的对比表征。在导航任务中,Depth-4网络仅使用到目标的欧几里得距离近似Q值,而Depth-64网络能够捕捉迷宫拓扑,并使用高Q值勾勒出可行路径。此外,扩展网络深度还提高了AI的泛化能力。在训练期间未见过的起始-目标对上进行测试时,较深的网络在更高比例的任务上取得了成功。
研究采用了来自ResNet架构的残差连接,每个残差块由四个重复单元组成,每个单元包含一个Dense层、一个层归一化层和Swish激活函数。网络深度被定义为架构中所有残差块的Dense层总数。在所有实验中,深度指的是actor网络和两个critic encoder网络的配置,这些网络被共同扩展。
本研究的主要贡献在于展示了一种将多种构建模块整合到单一强化学习方法中的方式,该方法展现出卓越的可扩展性。研究观察到性能显著提升,在半数测试环境中提升超过20倍,这对应着随模型规模增长而涌现的质变策略。虽然许多先前的强化学习研究主要关注增加网络宽度,但本方法成功解锁了沿深度轴扩展的能力,产生的性能改进超过了仅靠扩展宽度所能达到的。此外,研究表明更深的网络表现出增强的拼接能力,能够学习更准确的价值函数,并有效利用更大批量大小带来的优势。
然而,拓展网络深度是以消耗计算量为代价的。使用分布式训练来提升算力,以及剪枝蒸馏是未来的扩展方向。预计未来研究将在此基础上,通过探索额外的构建模块来进一步发展这一方法。
原文和模型
【原文链接】 阅读原文 [ 1654字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★☆


相关文章




