文章摘要
【关 键 词】 语音模型、开源、音频处理、人工智能、技术发展
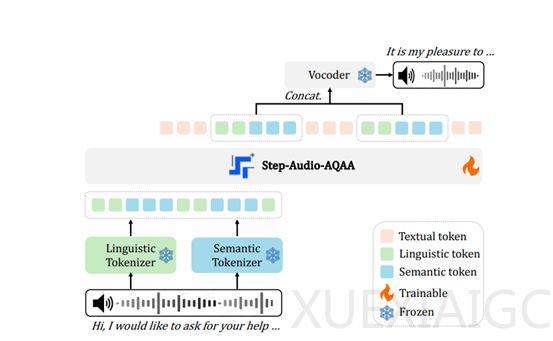
Step-Audio团队近期开源了一个端到端的语音大模型Step-Audio-AQAA,该模型能够直接理解音频输入并生成自然流畅的语音回答,而无需先将语音转换为文本。这一技术突破在人机音频交互领域具有重要意义,因为它能够更自然地模拟人类对话,提升用户体验。Step-Audio-AQAA的架构由双码本音频标记器、骨干LLM和神经声码器三个核心模块组成,每个模块在模型的功能实现中都扮演了关键角色。
双码本音频标记器是模型的前端模块,负责将输入的音频信号转换为结构化的标记序列。该模块包含两个不同的标记器:语言标记器和语义标记器。语言标记器专注于提取语音的高层次特征,如音素和语言属性,而语义标记器则捕捉语音的粗粒度声学特征,如情感和语调。这种双码本设计能够更好地捕捉语音信号中的复杂信息,并提高模型对语音的理解能力。
在双码本音频标记器将音频信号转换为标记序列后,这些标记序列会被送入骨干LLM。Step-Audio-AQAA的骨干LLM是一个预训练的1300亿参数多模态LLM,名为Step-Omni。Step-Omni的预训练数据涵盖了文本、语音和图像三种模态,使得模型能够同时处理多种类型的数据,并学习不同模态之间的关联。在处理来自双码本音频标记器的标记序列时,Step-Omni首先将双码本音频标记使用合并词汇表进行嵌入,随后通过多个Transformer块进行深度语义理解和特征提取。
最后,由骨干LLM生成的音频标记序列会被送入神经声码器模块,该模块负责将这些离散的音频标记合成为自然、高质量的语音波形。神经声码器采用了U-Net架构,集成了ResNet-1D层和Transformer块,能够高效地提取音频标记中的特征,并将其转换为连续的语音波形。这一设计灵感来源于CosyVoice 1.0中引入的最优传输条件流匹配模型,确保了生成的语音具有高质量和自然的表现力。
总体而言,Step-Audio-AQAA的开源标志着语音大模型技术的一个重要进展,它不仅能够直接处理音频输入,还能够生成自然流畅的语音回答,为人机交互提供了更加自然和高效的解决方案。这一技术的应用前景广阔,有望在智能助手、语音交互系统等领域发挥重要作用。
原文和模型
【原文链接】 阅读原文 [ 1380字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




