文章摘要
【关 键 词】 人工智能、多模态、强化学习、模型优化、技术探索
在人工智能技术快速发展的背景下,多模态大语言模型(MLLM)因其在图文理解、创作、知识推理及指令遵循方面的能力,成为数字化转型的重要推动力。小红书大模型团队在这一领域进行了深入探索,致力于使模型输出更贴近人类风格和价值观。团队采用基于人类反馈信号的强化学习方法(RLHF),特别是PPO(Proximal Policy Optimization)算法,以优化模型表现。
小红书资深技术专家于子淇在QCon上海2024大会上分享了团队在RLHF框架上的探索、设计和优化细节,并讨论了未来的计划与实践中的痛点,如PPO算法的资源消耗和训练精度敏感性。于子淇强调,RLHF通过人类反馈优化模型,减少幻觉,提升泛化能力,解决用户体验偏好问题。团队选择PPO算法因其在线生成数据能力强和算法效果好,尽管算法复杂,但已成为优化重点。
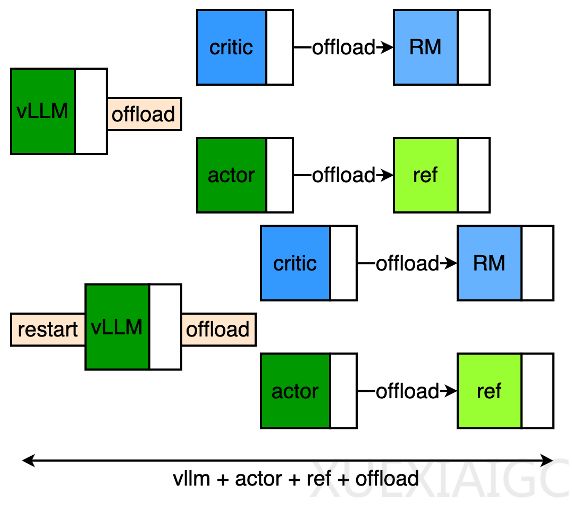
在框架设计中,基于actor/critic的offload同构组网架构提高了训练效率,通过模型参数和状态的迁移,降低了显存消耗。Pipeline优化针对make-experience阶段,通过流水线操作提升性能。精度对齐(RM精度要求)通过训推一致性实现,确保了训练和推理的完全一致。
于子淇还讨论了训推一致性的重要性,指出计算机浮点数的不精确表示可能导致模型输出差异,而训推一致性有助于bad case追溯。Medusa算法通过增加解码头并行预测多个token,提高了解码效率。团队通过多种技术手段提升了收敛速度和训练速度,包括advantage-whiten、pipeline设计、多模并行粒度调优等。
面对多模态LLM在RLHF训练中的挑战,团队通过合并TP/PP/CP/DP加速视觉部分计算,并利用prefetch将视觉部分视为数据预处理阶段,提升了性能。效果评估阶段,团队采用reward、value-loss、kl、response-len等指标衡量RLHF训练的成功。
未来,团队计划在训练速度优化和算法探索两个方向上进行迭代,包括深度流水线调度、更强的投机采样算法和更长文本支持等。于子淇认为,小红书大模型团队在RLHF训练框架上的探索和实践将对公司在大模型方向上的探索和应用产生积极影响,特别是在强化学习对VLM/LLM效果提升方面。
原文和模型
【原文链接】 阅读原文 [ 3816字 | 16分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




