文章摘要
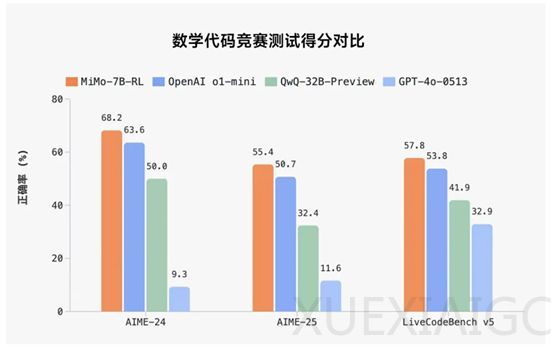
小米近日宣布进军大模型领域,并开源了一款名为MiMo-7B的模型。尽管MiMo-7B仅有70亿参数,但其在多个测试中表现优异,在数学AIME24/25中分别达到68.2分和55.4分,超过了OpenAI的o1-mini和阿里的QwQ-32B-preview。此外,在代码LiveCodeBench v5中也取得了57.8分的成绩。MiMo-7B在语言理解、科学问答和指令遵循等方面同样表现出色,是一款参数小、消耗低、性能强的模型,非常适合个人开发者和中小企业在本地部署使用。
MiMo-7B采用了标准的单向仅解码器Transformer架构,并结合了GQA、预RMS归一化、SwiGLU激活函数和RoPE技术来增强模型的推理能力。GQA技术提高了注意力机制的效率,RMS归一化加速了模型收敛,SwiGLU激活函数增强了模型的表达能力,而RoPE技术则优化了位置编码。然而,模型在推理过程中仍面临速度瓶颈,为解决这一问题,MiMo-7B引入了MTP模块,显著加速了解码过程。实验表明,MTP层的接受率高达90%,即使在极长输出的推理场景中也能实现快速解码。
在训练数据方面,MiMo-7B采用了多种策略生成合成推理数据,选择与STEM相关的内容,收集数学和代码问题,并加入一般领域的查询任务。通过三阶段数据混合策略,MiMo-7B构建了一个包含约25万亿个token的高质量预训练数据集。后训练阶段包括SFT和RL两个核心环节。SFT阶段通过高质量的标注数据对预训练模型进行调整,最终包含约500K个样本,充分利用了模型的上下文处理能力。RL阶段则通过精心整理的数学和编程问题数据集,采用GRPO算法进行强化学习,进一步优化了模型的策略。
小米在强化学习训练中引入了多项创新技术,移除KL损失、引入动态采样技术、采用Clip-Higher方法,以提升训练效果。这些改进不仅充分发挥了策略模型的潜力,还确保了训练的稳定性和有效性。目前,小米正在积极招募人才,以进一步推动大模型领域的发展。
原文和模型
【原文链接】 阅读原文 [ 1641字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章



