文章摘要
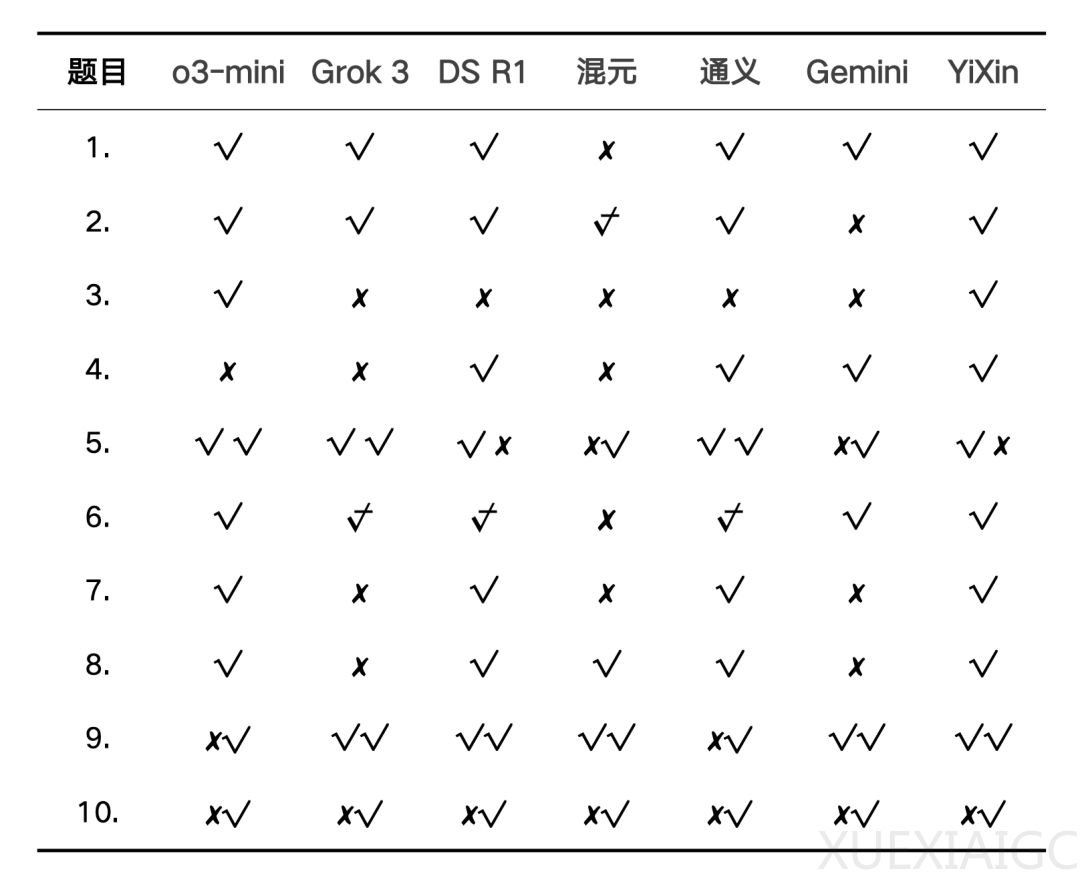
最近,针对国内外7款大模型进行了一场数学能力测试,测试题目主要来自“阿里巴巴全球数学竞赛”和“中国数学奥林匹克(CMO)”的真题,涵盖了多个数学领域,包括代数、几何、概率等。测试结果显示,大模型在复杂数学问题上的表现有了显著提升,尤其是在多步推理和开放性复杂应用题中,展现了较强的推理能力。然而,不同模型在解题风格上存在明显差异,部分模型如DeepSeek R1和YiXin-Distill-Qwen-72B的推理步骤较长,且容易出现截断情况,而o3-mini、Grok 3和通义 QwQ的解题步骤则相对简洁。
在测试过程中,部分模型出现了对题意理解偏差或符号误读的情况,但这些错误并非源于数学能力的不足,而是由于对问题的解读不够准确。尽管如此,模型在纠错能力上表现出色,能够在一定程度上容忍符号或公式的局部错误,并继续完成推理过程。此外,测试还发现,模型在处理中文问题时,推理过程有时会使用英文,这可能是由于训练数据的语言分布不均所致。
未来,大模型的数学能力可以通过插件扩展、垂直训练和交互式修正等方式进一步提升。例如,接入计算引擎如Wolfram Alpha可以弥补符号运算的短板,而针对数理逻辑构建专属微调数据集则能强化推理因果链。此外,允许用户实时指出错误步骤并动态调整解题路径,将有助于提高模型的解题准确性和用户体验。
对于学生群体,大模型可以作为一个快速验证基础题答案的工具,但在处理复杂问题时,仍需警惕模型的“自信式错误”,并保持独立思考。教育工作者则需要设计更“反套路”的题目,以检验AI辅助下的真实学习效果。开发者则应优化提示词设计,明确解题边界,避免模型过度“脑补”。
总体而言,大模型的数学能力已经从“玩具级”迈入“工具级”,并逐步走向可信赖的“研究级”。未来的竞争将聚焦于如何更精准地平衡“思维模拟”与“事实严谨性”,这一领域的进一步发展值得期待。
原文和模型
【原文链接】 阅读原文 [ 2550字 | 11分钟 ]
【原文作者】 AI产品阿颖
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




