完整的671B MoE DeepSeek R1怎么塞进本地化部署?详尽教程大放送!
文章摘要
【关 键 词】 深度学习、模型部署、量化技术、硬件配置、性能优化
李锡涵在其AIxiv专栏中分享了如何将DeepSeek R1 671B模型部署到本地环境的详细教程。DeepSeek R1因其出色的性能而广受欢迎,但本地部署可以提供更个性化的服务。通常,人们使用的是蒸馏后的8B/32B/70B版本,这些版本基于微调后的Llama或Qwen模型,并未完全发挥DeepSeek R1的潜力。然而,通过量化技术,完整的671B MoE模型可以被压缩,降低部署难度,甚至能在消费级硬件上运行。
为了实现本地部署,李锡涵采用了Unsloth AI提供的“动态量化”版本,该版本通过4-6bit量化关键层,以及1-2bit量化混合专家层(MoE),将模型体积大幅缩减至131GB(1.58-bit量化),使得在Mac Studio等硬件上运行成为可能。他测试了两个模型:DeepSeek-R1-UD-IQ1_M(1.73-bit动态量化,158GB)和DeepSeek-R1-Q4_K_M(4-bit标准量化,404GB)。Unsloth AI提供了四种动态量化模型,用户可根据硬件条件选择。
部署大模型时,内存和显存容量是主要瓶颈。李锡涵建议的配置包括至少200GB(对于DeepSeek-R1-UD-IQ1_M)和500GB(对于DeepSeek-R1-Q4_K_M)的内存+显存。他使用ollama进行模型部署,该工具支持CPU与GPU混合推理,允许将模型部分层加载至显存加速。他的测试环境包括四路RTX 4090显卡和四通道DDR5内存,以及ThreadRipper 7980X CPU,短文本生成速度为7-8 token/秒(纯CPU推理时为4-5 token/秒),长文本生成速度降至1-2 token/秒。
他还提供了更具性价比的硬件选项,如Mac Studio、高内存带宽的服务器和云GPU服务器。对于硬件条件有限的用户,可以尝试更小的1.58-bit量化版(131GB),在单台Mac Studio或2×Nvidia H100 80GB上运行,速度可达10+ token/秒。
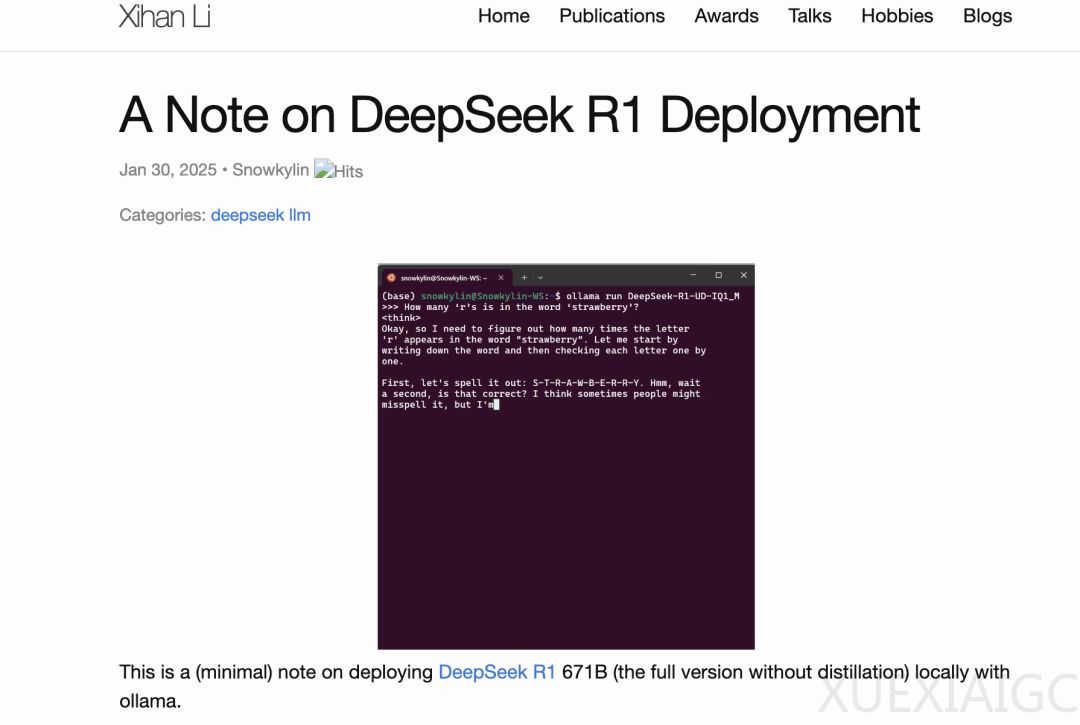
部署步骤包括下载模型文件、安装ollama、创建Modelfile文件、创建ollama模型和运行模型。李锡涵还提供了可选的Web界面安装指南。他的初步观察表明,1.73-bit和4-bit的完整版模型在经典任务中表现良好,且优于蒸馏版模型。4-bit版本相对更保守,倾向于拒绝攻击性或无厘头的提示。1.73-bit版本偶尔会生成格式混乱的内容,而全量模型运行时CPU利用率极高,GPU利用率低,表明性能瓶颈主要在于CPU和内存带宽。
最后,李锡涵建议,如果无法将模型完全加载至显存,1.73-bit动态量化版本更具实用性,速度快且资源占用少。他建议在消费级硬件上用于轻量任务,避免需要长思维链或多轮对话的场景。
原文和模型
【原文链接】 阅读原文 [ 3058字 | 13分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


