文章摘要
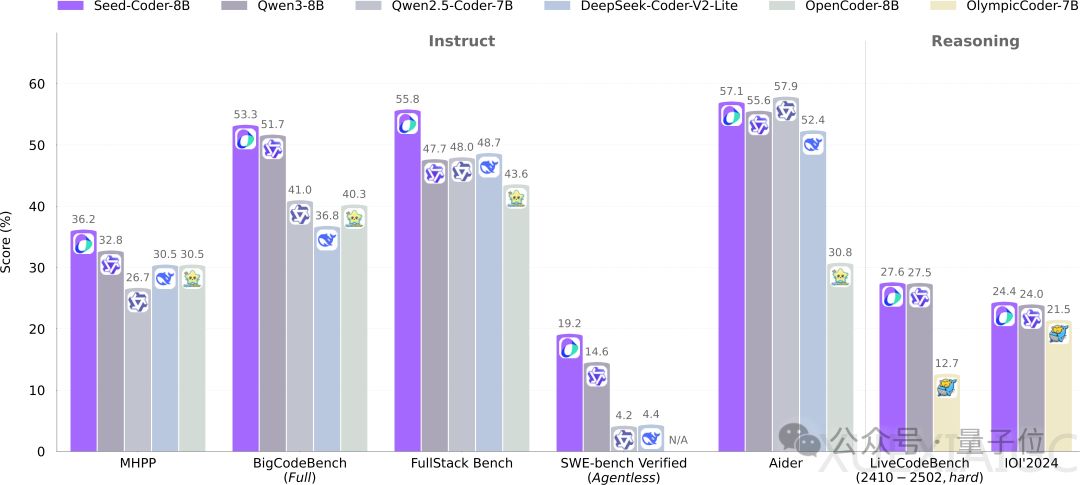
字节跳动首次开源了其代码模型Seed-Coder,该模型规模为8B,超越了Qwen3,并在多个基准测试中取得了领先地位。Seed-Coder通过自身生成和筛选高质量训练数据,显著提升了代码生成能力,证明了“只需极少人工参与,LLM就能自行管理代码训练数据”的理念。该模型包含三个版本:Base、Instruct和Reasoning,其中Instruct在编程任务中表现出色,而Reasoning在IOI 2024竞赛中超越了QwQ-32B和DeepSeek-R1。Seed-Coder的上下文长度为32K,使用了6T tokens进行训练,并采用MIT开源协议,完整代码已发布在Hugging Face。
Seed-Coder的前身是doubao-coder,采用Llama 3结构,参数量为8.2B,6层,隐藏层大小为4096,采用分组查询注意力(GQA)机制。模型的关键创新在于其数据处理方式,Seed团队提出了一种“模型中心”的数据处理策略,通过模型从GitHub和网络档案中爬取原始代码数据,经过多个处理步骤后输出最终的预训练数据。数据处理分为四个类别:文件级代码、仓库级代码、Commit数据和代码相关网络数据。在预处理阶段,系统通过SHA256哈希和MinHash算法进行去重,并使用Tree-sitter等语法解析器检查文件,丢弃包含语法错误的文件,最终减少了约98%的原始数据量。
在质量过滤阶段,Seed-Coder使用了一个经过22万+份代码文档特殊训练的评分模型来过滤低质量代码文件。评分模型以DeepSeek-V2-Chat为基础,评价指标包括可读性、模块性、清晰度和可重用性,最终过滤掉了得分最低的约10%文件,得到了支持89种编程语言、包含约1万亿个独特token的语料库。对于Commit数据,Seed-Coder从14万个高质量GitHub仓库中收集了7400万个提交记录,并将每个提交样本格式化为一个代码变更预测任务,最终获得了约1000亿token的提交数据语料库用于预训练。
对于从网络获取的数据,Seed-Coder提出了一个专门的提取框架,通过精确和近似去重技术,以及启发式规则来剔除低质量文档。在质量过滤阶段,框架采用两个互补策略来确保数据质量:首先是识别代码相关性,然后评估已识别内容的内在质量。最终,系统构建了一个约1.2万亿tokens的网络数据语料库。Seed-Coder的预训练分为两个阶段:第一阶段使用文件级代码和代码相关网络数据进行常规预训练,第二阶段使用所有四个类别的数据进行持续预训练,并额外引入了高质量数据集和长上下文数据集,以增强性能并进行对齐。
基于基础模型,Seed团队还开发了Seed-Coder的两个特殊变体:指令模型(-Instruct)和推理模型(-Reasoning)。指令模型通过监督微调和直接偏好优化增强指令遵循能力,而推理模型通过长链条思维强化学习提升复杂编程任务中的多步推理能力。这两个变体进一步扩展了Seed-Coder的实用性。
字节跳动近期在开源和开放方面动作频频,除了Seed-Coder,还发布了视频生成模型Seaweed和深度思考模型Seed-Thinking-v1.5,并与清华合作推出了电脑操作智能体UI-TARS。这些举措表明字节跳动正在通过开源和原始性创新推动AI技术的普惠化,同时也反映了AI领域的新风向:开源、开放、原始性创新和AI普惠。
原文和模型
【原文链接】 阅读原文 [ 2609字 | 11分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




