文章摘要
【关 键 词】 OmniHuman、AI数字人、双系统论、多模技术、内容创作
想象与能“眉来眼去”、进行情绪交流的AI虚拟人聊天并非科幻,字节跳动智能创作实验室推出的OmniHuman – 1.5宣告“数字人新王”登基。
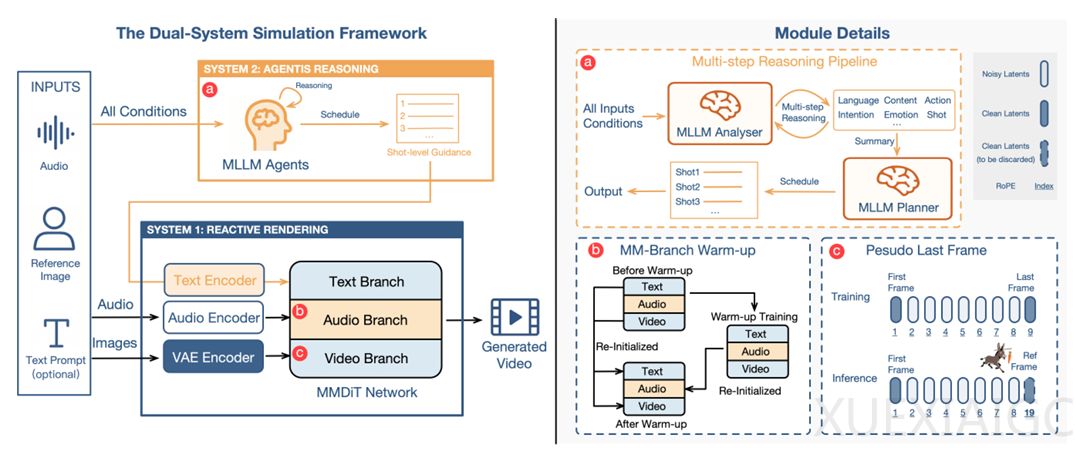
此前市面上的AI数字人多是“精致的提线木偶”,仅具备“条件反射式”的快反应,缺乏需要逻辑推理、深思熟虑的慢反应,动作虽逼真但缺少“灵魂”,表情和动作不自然。字节跳动团队以“双系统理论”为底层逻辑,构建“认知引擎”。用多模态大语言模型充当虚拟人的“思考系统”(System 2),它会分析人物信息、音频内容和情绪等,整合后规划出逻辑严密的“动作剧本”;再由多模态扩散Transformer(MMDiT)架构作为“执行系统”(System 1),将文字指令、原始音频信号和人物视觉特征深度融合。
为解决多模态信息融合难题,OmniHuman – 1.5采用两大技术:“伪最后帧”设计和对称的多模态分支架构。“伪最后帧”设计抛弃静态参考图,训练模型根据视频片段的“第一帧”和“最后一帧”预测中间帧,实际使用时将参考图置于“最后一帧”位置,保证人物身份稳定的同时释放动作自由度。对称的多模态分支架构为音频构建独立处理分支,通过共享自注意力机制让文字、音频、视频信息在MMDiT架构各层互动对齐,并采用“两阶段预热”策略实现稳定训练。
从效果来看,OmniHuman – 1.5在各项指标上领先老一代技术和竞争对手。客观数据显示,其在衡量视频整体质量、唇音同步、手部动作自然度和丰富度等方面表现出色;主观评测中,用户偏好度高,生成的视频在动作自然度和语义一致性上优势明显。它还能处理多人互动场景和非人类角色,生成的视频时长超一分钟且可无缝衔接。
OmniHuman – 1.5的发布有望引爆全新内容创作时代,在电影电视、教育、营销电商、游戏社交等行业具有广阔商业前景,将内容创作门槛拉低,使AI数字人从“看着像”进化到“有神韵”。
原文和模型
【原文链接】 阅读原文 [ 2159字 | 9分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★★


相关文章




