字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%
文章摘要
【关 键 词】 超连接、梯度消失、Dense模型、MoE模型、性能提升
字节跳动豆包大模型团队最近提出了一种名为超连接(Hyper-Connections)的新方法,旨在替代传统的残差连接,以解决梯度消失和表示崩溃之间的权衡问题。超连接通过动态调整不同层之间的连接权重,显著提升了Dense模型和MoE模型在预训练中的性能,最高可加速收敛速度80%。
超连接的核心在于引入可学习的深度连接和宽度连接,允许模型动态调整层间的连接强度,甚至重新排列网络层次结构。这种方法分为静态和动态两种形式,其中动态超连接(DHC)的效果更佳。在技术细节上,超连接将网络输入扩展为多个隐向量,并通过超连接矩阵对这些隐向量建立深度和宽度连接。超连接矩阵的元素可以是静态的,也可以动态依赖于输入。
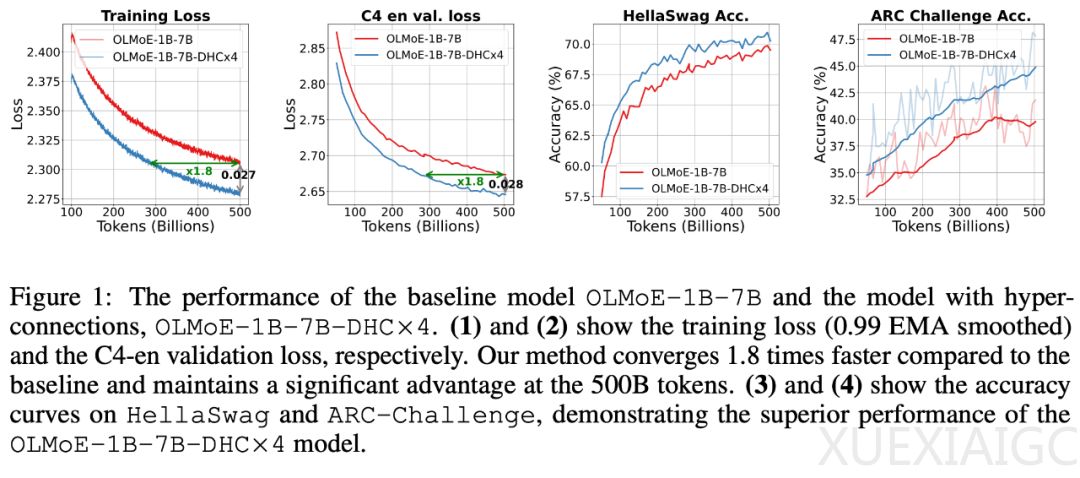
研究团队通过实验发现,超连接在大规模语言模型预训练和视觉任务中都表现出显著的性能提升。例如,在1B和7B的Dense模型实验中,使用超连接的模型训练更稳定,消除了训练loss的spikes。在7B候选激活1.3B的MoE模型实验中,下游指标全面提升,ARC-Challenge上提升了6个百分点。
超连接的引入几乎不增加额外的计算开销或参数量,具有广泛的应用潜力,可推广到不同任务上,包括多模态理解和生成基座模型等。团队关注底层问题,尤其在大规模语言模型和多模态方面,期望实现更多突破。
原文和模型
【原文链接】 阅读原文 [ 2292字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

