文章摘要
【关 键 词】 ViTamin、混合架构、零样本性能、多模态大模型、智能创作团队
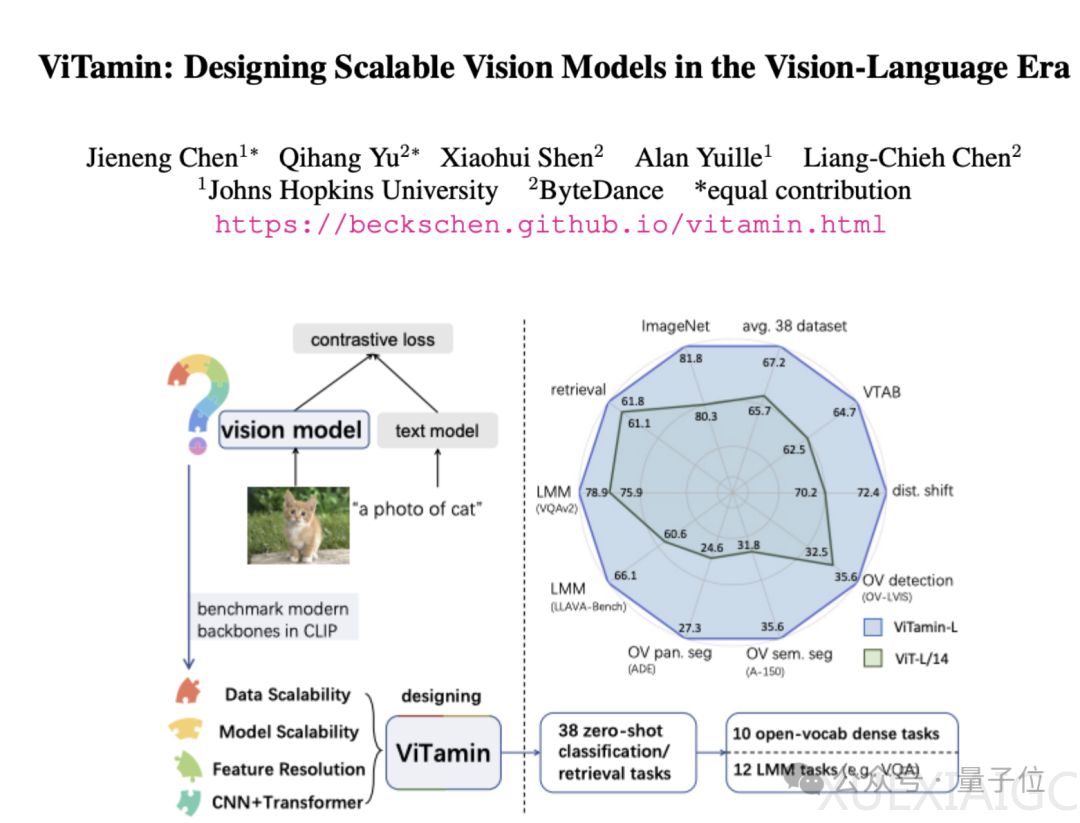
文章介绍了字节跳动提出的新基础模型ViTamin,专为视觉语言时代设计。ViTamin在ImageNet零样本准确率上比ViT提高了2.0%,在多个基准任务上表现出色。ViTamin-XL在参数规模较小的情况下取得了比参数规模大的EVA-E更好的结果。该模型采用了混合架构,结合了MBConv Blocks和Transformer Blocks。研究人员通过对比ViT、ConvNeXt和CoAtNet等模型在数据可扩展性、模型可扩展性、特征分辨率和混合架构等方面的测试,得出了设计ViTamin模型的关键发现。ViTamin在零样本性能、开放词汇检测和分割、多模态大模型等任务上表现优异,超越了其他模型。智能创作团队是字节跳动的AI & 多媒体技术团队,通过结合公司的业务场景和技术资源,实现了前沿算法到产品的闭环,为公司内部各业务提供内容理解、内容创作、互动体验等能力。他们已经向企业开放了技术能力和服务,并提供了论文链接和项目主页。
原文和模型
【原文链接】 阅读原文 [ 1600字 | 7分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-3.5-turbo-0125
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



