文章摘要
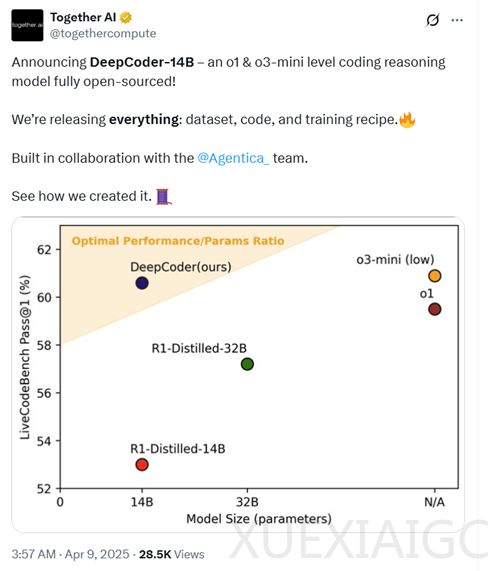
今天凌晨4点,著名大模型训练平台Together AI和智能体平台Agentica联合开源了新模型DeepCoder-14B-Preview。该模型仅有140亿参数,但在知名代码测试平台LiveCodeBench的测试中取得了60.6%的分数,高于OpenAI的o1模型(59.5%),略低于o3-mini(60.9%)。在Codeforces和AIME2024等平台的评测数据同样表现出色,几乎与o1和o3-mini持平。DeepCoder-14B-Preview的开源不仅包括模型权重,还公开了训练数据集、训练方法、训练日志和优化方法,为开发者提供了深入了解模型开发流程的机会。
DeepCoder-14B-Preview基于Deepseek-R1-Distilled-Qwen-14B模型,通过分布式强化学习(RL)进行了微调。在开发过程中,研究人员构建了一个包含24K个可验证编程问题的高质量训练数据集,涵盖了TACOVerified问题和PrimeIntellect的SYNTHETIC-1数据集中的验证问题。为确保数据质量,每个问题都通过外部官方解决方案进行程序化验证,并且数据集经过测试过滤和去重处理,确保每个问题至少包含5个单元测试,并删除了重复问题。
在代码强化学习训练中,DeepCoder使用了两种沙盒环境:Together Code Interpreter和本地代码沙盒。Together Code Interpreter是一个快速高效的环境,支持100多个并发沙盒和每分钟1000多个沙盒执行,而本地代码沙盒则遵循官方LiveCodeBench仓库的评估代码,确保结果与现有排行榜的一致性。奖励函数采用了稀疏结果奖励模型(ORM),只有当生成的代码通过所有采样单元测试时,才会给予奖励,这种设计避免了模型通过奖励黑客行为获取不准确的奖励信号。
为了提升训练稳定性,DeepCoder采用了改进版的GRPO+算法,通过消除熵损失和KL损失、引入过长过滤和上限裁剪等技术,使得模型在训练过程中保持稳定的熵值,避免训练崩溃。此外,DeepCoder-14B-Preview采用了迭代上下文扩展技术,从16K的上下文窗口逐步扩展到64K,最终在64K上下文中评估时达到了60.6%的准确率。
为了加速端到端的RL训练,DeepCoder团队开源了verl-pipeline,通过一次性流水线技术实现了训练、奖励计算和采样的完全流水线化,显著提高了训练效率。这些优化使得训练时间减少了2倍,特别是在需要运行数千个测试用例的编码任务中,训练效率得到了显著提升。
DeepCoder-14B-Preview的开源获得了高度评价,网友认为这不仅是一次真正意义上的开源,还在广义信赖域策略优化算法(GRPO)和采样流水线效率方面进行了多项改进。Together AI作为一家成立于2022年的云大模型平台,支持超过200种开源AI模型,并拥有超过3.6万块GB200 NVL72组成的超大GPU算力群。近期,Together AI刚刚完成了3.05亿美元的B轮融资,估值从去年的12.5亿美元翻倍至33亿美元。
原文和模型
【原文链接】 阅读原文 [ 1183字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆


相关文章




