如何从头开始编写LoRA代码,这有一份教程
模型信息
【模型公司】 OpenAI
【模型名称】 gpt-3.5-turbo-0125
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 LoRA、微调、大语言模型、PyTorch、性能优化
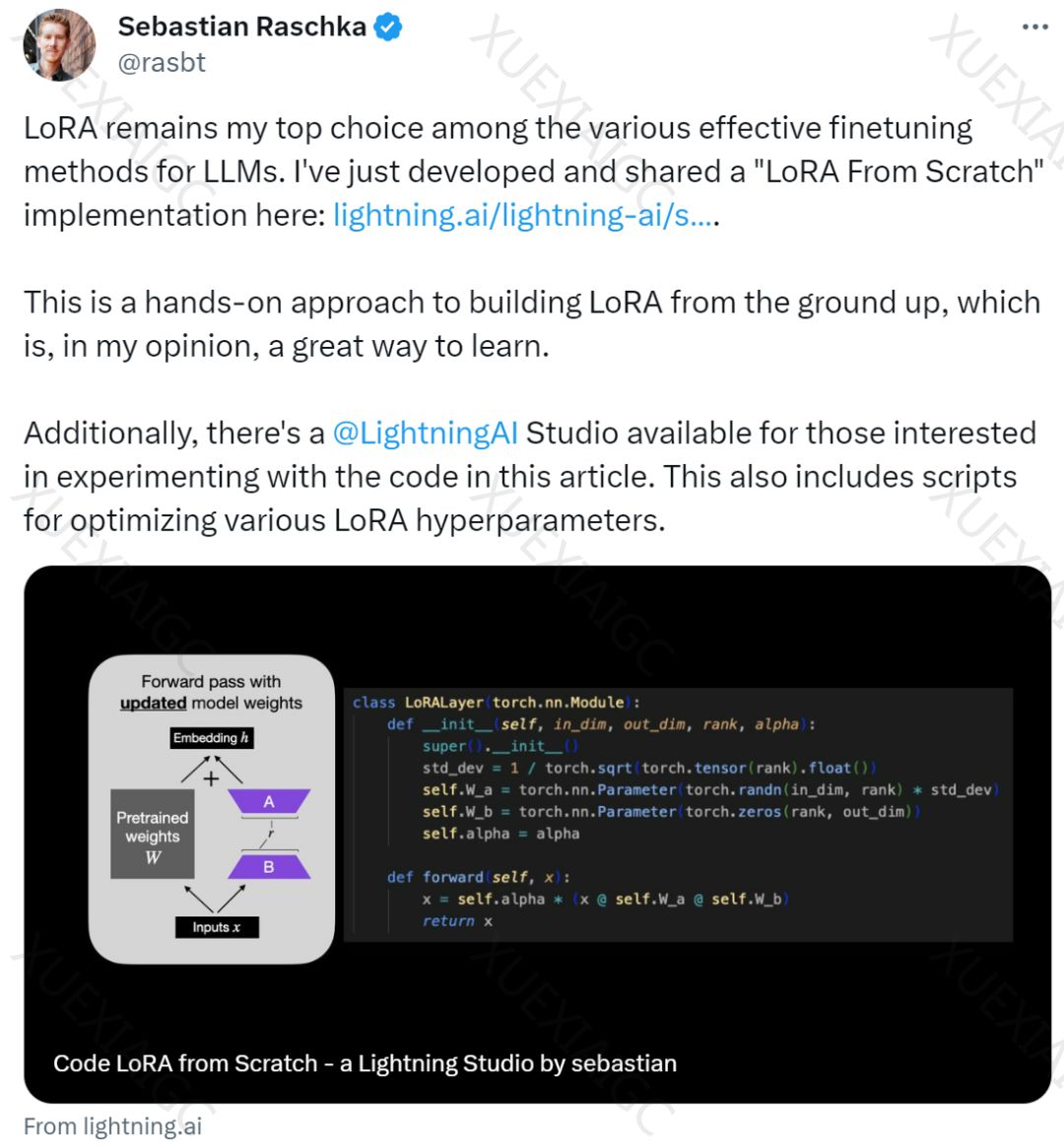
本文介绍了一种名为 LoRA(Low-Rank Adaptation) 的微调技术,用于微调大语言模型(LLM)。LoRA 是一种流行的技术,通过仅更新一小部分低秩矩阵而不是整个神经网络的参数,大大减少了训练模型所需的计算量。作者Sebastian Raschka 认为 LoRA 是一种有效的LLM微调方法,并撰写了一篇博客《Code LoRA From Scratch》来介绍如何从头开始构建 LoRA。在实验中,Sebastian 使用 LoRA 对 DistilBERT 模型进行微调,并应用于分类任务。 LoRA 的测试准确率达到了 92.39%,明显优于仅微调模型最后几层的方法(86.22%的测试准确率)。
文章详细介绍了如何从头开始编写 LoRA,包括 LoRA 层的代码实现和如何在 PyTorch 模型中应用 LoRA。通过将现有的线性层替换为结合了原始线性层和 LoRALayer 的 LinearWithLoRA 层,可以实现 LoRA 的应用。作者还提供了如何使用 LoRA 进行微调的步骤,以及如何与传统微调方法进行比较。在实验中, LoRA 的性能优于传统微调最后几层的方法,同时使用的参数量却少了很多。通过优化 LoRA 的配置,可以进一步提高性能,得到更高的验证准确率和测试准确率。
总的来说, LoRA 作为一种高效的LLM微调方法,通过减少参数更新的数量来提高模型性能,同时减少了计算成本。通过本文提供的教程和实验结果,读者可以更好地理解 LoRA 的原理和应用,以及如何在实际项目中使用 LoRA 进行微调,从而提高模型的性能和效率。
原文信息
【原文链接】 阅读原文
【阅读预估】 1379 / 6分钟
【原文作者】 机器之心
【作者简介】 专业的人工智能媒体和产业服务平台

相关文章



