奖励模型终于迎来预训练新时代!上海AI Lab、复旦POLAR,开启Scaling新范式
文章摘要
【关 键 词】 强化学习、奖励模型、策略判别、预训练、泛化能力
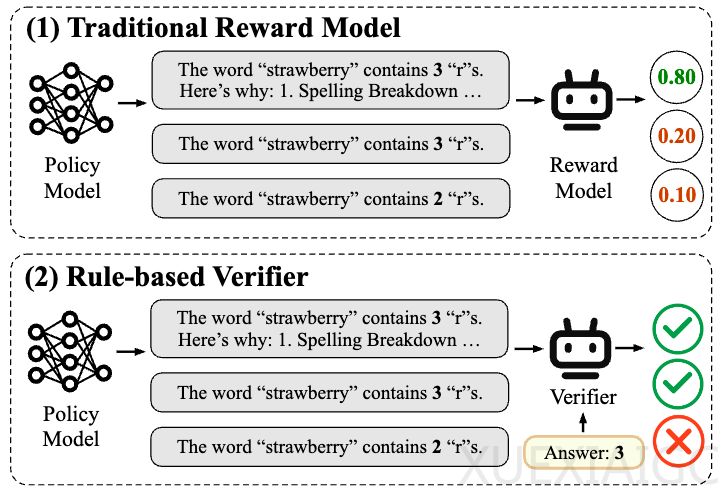
在大语言模型的后训练阶段,强化学习是提升模型能力、对齐人类偏好的核心方法,但奖励模型的设计与训练仍是关键瓶颈。当前主流方法包括“基于偏好的奖励建模”和“基于规则的验证”,但前者受限于数据成本与泛化能力,后者难以适应开放域任务。
为解决这一问题,上海人工智能实验室与复旦大学团队提出了预训练奖励模型POLAR,其核心创新是策略判别学习(Policy Discriminative Learning)。该方法通过对比学习衡量候选策略与最优策略的分布距离,摆脱了对人工标注偏好的依赖。POLAR的预训练阶段仅需自动化合成数据,通过同一策略生成的轨迹作为正例、不同策略的轨迹作为负例,隐式建模策略差异。微调阶段则引入少量人类偏好数据对齐目标。
实验表明,POLAR在闭式与开放任务中均表现出色。例如,在数学推理场景中,POLAR能精准区分答案正确性、逻辑完整性和错误类型;在开放创作任务中,它能识别成语使用的合规性与多样性。偏好评估中,POLAR-1.8B以极小参数量超越参数量15倍的基线模型;在强化微调(RFT)应用中,POLAR-7B使Llama-3.1-8B模型性能平均提升9%。
POLAR还展现出与语言模型预训练相似的Scaling Laws,验证集损失随计算量增加呈幂律下降,预示其扩展潜力。这一方法为通用强化学习提供了新范式,通过解耦绝对偏好与策略距离,实现了奖励模型的高效预训练与泛化应用。
原文和模型
【原文链接】 阅读原文 [ 3712字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



