多模态扩散模型开始爆发,这次是高速可控还能学习推理的LaViDa
文章摘要
【关 键 词】 LaViDa模型、扩散模型、视觉语言、文本填空、训练评估
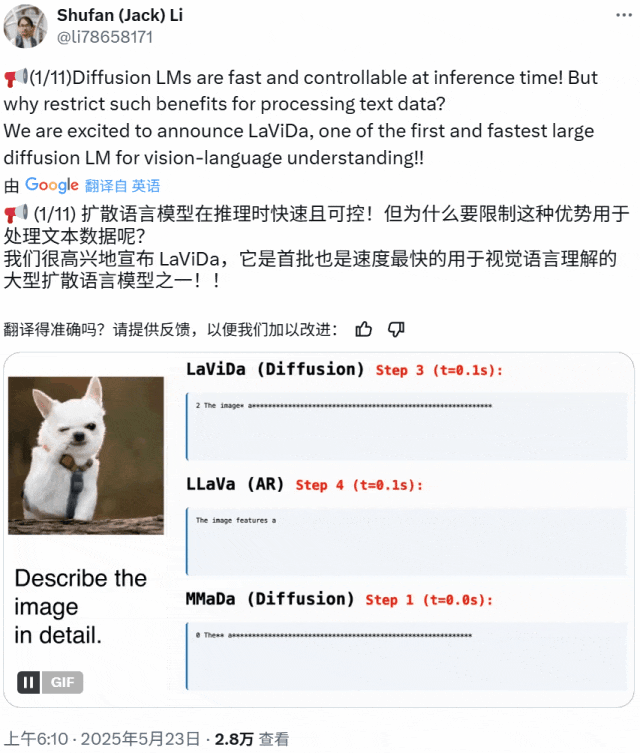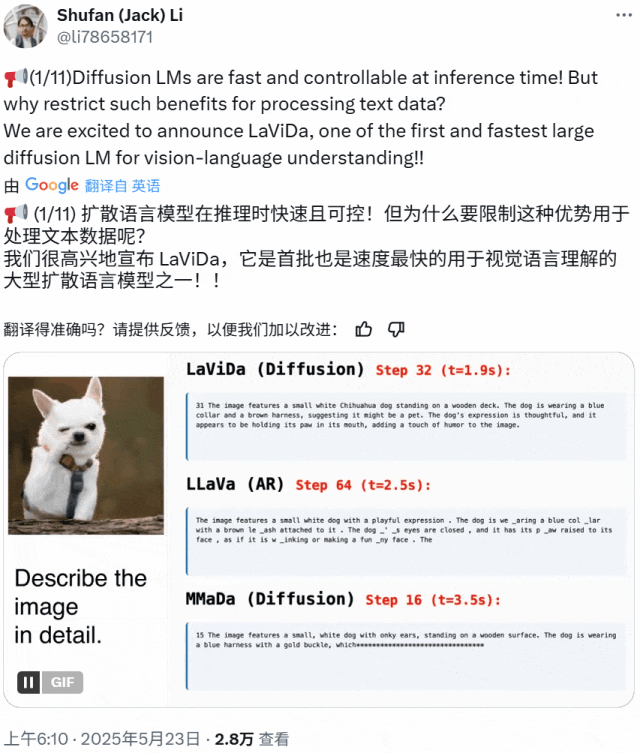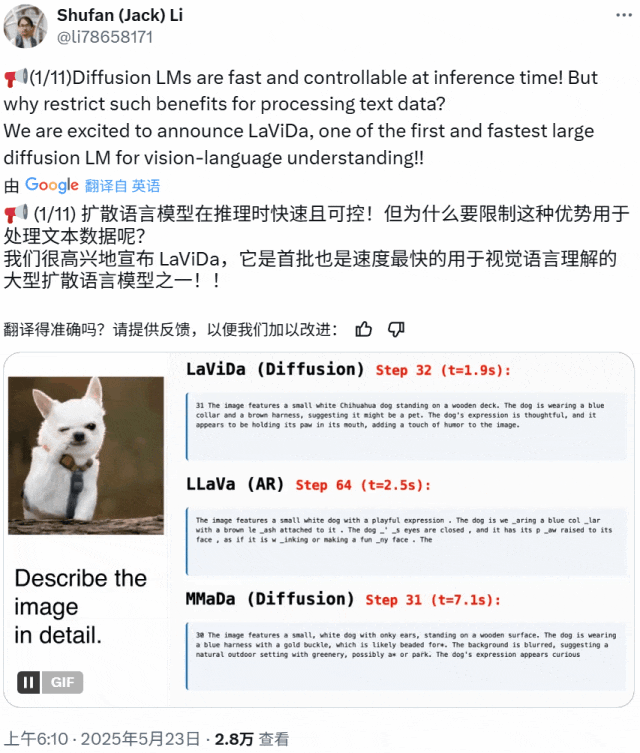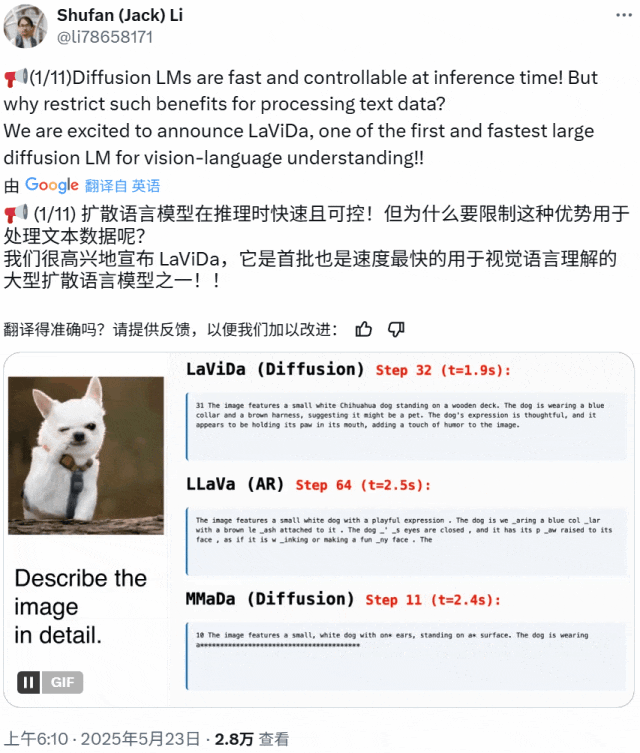
近期基于扩散模型的视觉 – 语言模型 LaViDa 诞生,继承了扩散语言模型高速且可控的优点,实验表现出色。
当前流行的 VLM 多基于自回归(AR)的大型语言模型(LLM),按顺序生成 token 导致推理速度慢,难以处理需要双向上下文或结构约束的任务。而离散的扩散模型(DM)将文本生成视为在离散 token 上的扩散过程,相比自回归 LLM 能解决其局限性,可灵活平衡速度与质量,适合文本填空等任务。
LaViDa 全称为“带掩码的大型视觉 – 语言扩散模型”,来自加利福尼亚大学洛杉矶分校、松下、Adobe 和 Salesforce,是首批基于扩散的 VLM 之一。它由视觉编码器和扩散语言模型组成,二者通过 MLP 投射网络连接。视觉编码器将图像分成多个视图独立编码,应用平均池化减少嵌入数量,经投射网络处理得到最终视觉上下文;扩散语言模型是多层 Transformer,输入包括投射的视觉嵌入等,使用扩散语言建模目标。
LaViDa 采用两阶段训练流程。预训练阶段仅更新投射算子,微调阶段对所有组件端到端联合训练。实验在多种视觉 – 语言任务上进行评估,LaViDa 在一般任务、推理、科学等类别任务上展现出极具竞争力的性能。在一般性视觉 – 语言理解方面,LaViDa – L 在 MMMU 上获最高分;在推理任务中超越规模相似的基线模型;在科学任务上表现优异;但在 OCR 方面落后于一些最新自回归模型,原因是使用平均池化压缩视觉 token 导致细粒度空间信息丢失。
为提升推理能力,团队用蒸馏的 CoT 样本进行第三阶段训练,得到 LaViDa – Reason,在多个推理数据集上优于 LaViDa。在文本填空方面,LaViDa 提供强大可控性,通过额外训练得到 LaViDa – FIM,实现长度可变的补全,在有约束诗歌生成任务上对比自回归模型表现更佳。此外,LaViDa 可通过控制离散化步数 K 灵活实现速度与质量的权衡,在不同 NFE 值下表现出速度与质量的不同平衡。
原文和模型
【原文链接】 阅读原文 [ 2988字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1.5-pro-32k
【摘要评分】 ★★★★★


相关文章




