多模态大模型有了统一分割框架,华科PSALM多任务登顶,模型代码全开源
文章摘要
【关 键 词】 多模态大模型、图像分割、PSALM模型、性能优异、参数优化
最近,多模态大模型(LMM)在视觉-语言任务上取得了显著的进展,尤其是在视觉场景下的应用。然而,将LMM应用于计算机视觉任务,特别是图像分割方面,仍面临挑战,因为大多数LMM目前仅限于文本输出,不足以处理图像分割的细粒度任务。图像分割任务的多样性和复杂性,如实例分割、指代分割(RES)和交互式分割,要求模型能够有效地统一和处理不同的输入输出格式,这是一个尚未解决的问题。
为了应对这些挑战,华中科技大学的研究团队开发了PSALM模型,旨在通过一个统一的框架处理多种类型的图像分割任务。PSALM模型的设计理念是实现分割任务的全面覆盖,并且展现了在未见分割任务上的零样本泛化能力。PSALM模型具有以下特点:
- 参数优化:PSALM采用了Swin-Base结合Phi-1.5(1.3B参数)的模型组合,相比传统的ViT-L和Vicuna-7B/Llama2-13B模型更为高效。
- 多任务统一:PSALM的结构设计灵活,能够统一多种分割任务的输入形式,并支持多任务联合训练,取得相互促进的效果。
- 性能优异:PSALM在多个已见分割任务上展现出强大性能,并在未见开放场景任务中表现出零样本泛化能力。
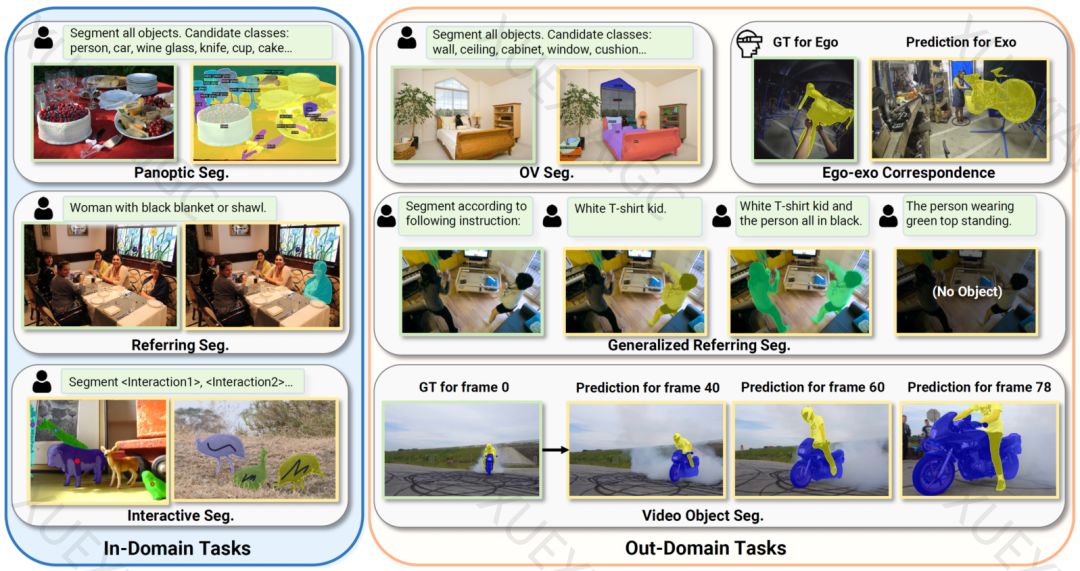
PSALM模型的工作原理包括图像编码器、大语言模型(LLM)和mask生成器。模型将LLM的输入分为四个部分:图片特征、任务指令提示、任务条件提示以及一组可学习的mask tokens。通过这种方式,PSALM能够处理包括语义分割、全景分割、指代分割和交互式分割等多种任务。
在性能方面,PSALM在多个基准测试集上取得了SOTA的性能,包括RefCOCO、RefCOCO+和RefCOCOg上的指代分割任务。此外,PSALM在COCO-val上与现有的SOTA模型进行比较,展现了竞争力强的结果。对于交互式分割任务,PSALM在COCO-Interactive数据集上取得了SOTA的效果。
PSALM还展示了在开放词表分割、通用指代分割、视频目标分割以及多视角Ego-Exo匹配分割任务上的零样本泛化能力,证明了其对未知任务的适应性。模型和训练代码已经开源,研究人员可以通过提供的链接访问。
总结来说,PSALM模型是多模态大模型在统一图像分割领域的一次积极尝试,它在参数优化、性能展示以及泛化能力方面均取得了显著成果。PSALM的创新架构和条件提示机制,使其能够灵活处理多样化的输入输出需求,在各种基准任务中取得优异的成绩。
原文和模型
【原文链接】 阅读原文 [ 1676字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 gpt-4
【摘要评分】 ★★★★☆


相关文章


