多模态大模型不够灵活,谷歌DeepMind创新架构Zipper:分开训练再「压缩」
文章摘要
【关 键 词】 多模态生成、Zipper架构、模态融合、解码器模型、性能评估
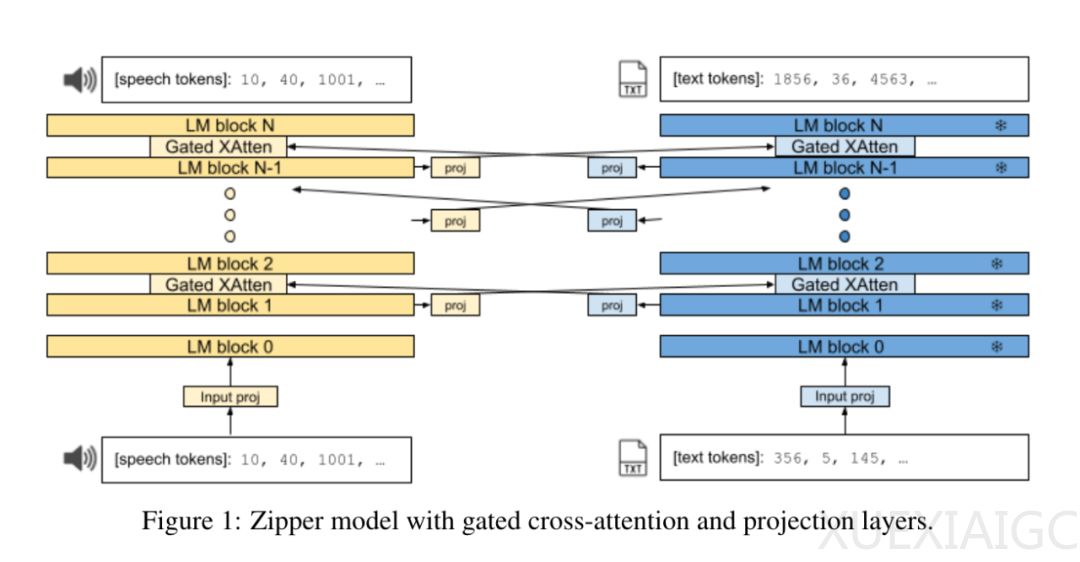
近期研究表明,通过训练纯解码器生成模型,可以成功地生成包括音频、图像和状态-动作序列在内的多种模态的新序列。这些模型通常采用词汇扩展方法实现多模态表征,然而这种方法在模态融合方面存在一定局限性,如难以在预训练后添加新模态,缺乏灵活性等。针对这些问题,Google DeepMind 提出了Zipper新型架构,该架构由多个单模态预训练解码器模型组成,通过交叉注意力机制实现模态融合。
Zipper 利用丰富的无监督单模态数据,在单一模态中进行预训练,随后通过有限的跨模态数据进行微调,以此实现多模态生成能力。这种设计使得预训练的纯解码器模型能灵活地重复使用和再利用于新的多模态组合。Zipper 的关键特点在于其模块化设计,通过门控交叉注意力层将多个解码器“压缩”在一起,实现模态间的信息交互。
在实验部分,研究者在自动语音识别(ASR)和文本到语音(TTS)任务上评估了Zipper的性能。结果表明,Zipper 在ASR任务上的性能与词汇扩展方法相当,而在TTS任务上,Zipper 明显优于单解码器模型,显著提高了模态生成能力。
具体来说,在ASR任务中,Zipper在测试集上的性能与基线模型相近,但在噪音环境下的性能略有下降。在TTS任务中,Zipper模型通过解冻语音骨干网络进行微调,显著提高了模型性能,验证了微调语音骨干网络参数的有效性。
综上所述,Zipper 架构为多模态融合提供了一种新的解决方案,其实验结果展示了在ASR和TTS任务上的应用潜力。这一研究为后续多模态融合技术的发展提供了有益启示。
原文和模型
【原文链接】 阅读原文 [ 2806字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章




