多元推理刷新「人类的最后考试」记录,o3-mini(high)准确率最高飙升到37%
文章摘要
【关 键 词】 推理模型、多元推理、基准测试、自动验证、性能提升
近年来,DeepSeek R1、OpenAI o1/o3等大语言模型在数学和编程领域的推理能力取得显著进展,但在国际数学奥林匹克竞赛(IMO)组合问题、抽象推理语料库(ARC)谜题及人类最后考试(HLE)等复杂基准测试中仍面临挑战。针对这一问题,研究者提出结合多种模型与方法的多元推理策略,通过自动验证机制和强化学习技术显著提升模型性能。
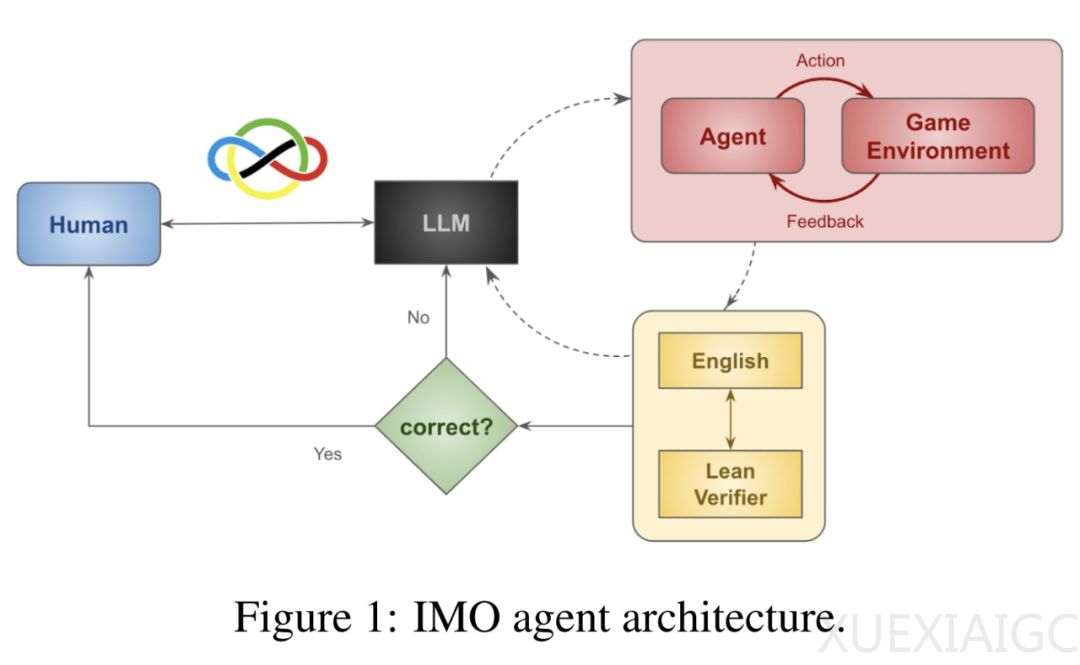
在方法设计上,研究者通过交互式定理证明器Lean对IMO问题进行形式化验证,利用代码自动检测ARC谜题解决方案,并采用best-of-N算法优化HLE问题的响应。该方法包含三个核心创新:首先,聚合8种不同方法(如LEAP、Z3、MoA等)实现多元推理,使IMO组合题验证准确率从33.3%跃升至77.8%;其次,通过测试时模拟将组合问题转化为可交互游戏环境,结合深度强化学习生成额外训练数据;第三,建立代码图元学习机制,动态调整代理图结构和超参数。
实验数据显示,该框架在三大基准测试中取得突破性进展:对于IMO未污染的9道组合题,o3-mini模型通过多元方法将准确率从33.3%提升至77.8%;在400个ARC评估谜题中,16种模型组合解决了人类未能破解的80%难题,并攻克o3 high模型失败的26.5%案例;针对HLE随机抽取的100个问题,best-of-N拒绝采样使o3-mini整体准确率达到37%,数学类问题准确率提升至33.3%。
研究还揭示语言模型的第三条扩展定律:可验证问题的性能与模型方法多样性呈正相关,这为后续研究提供新的优化方向。前两条定律分别涉及模型参数规模、数据量与性能的关系,以及测试算力投入对推理能力的增强效应。当前成果表明,通过自动验证机制与强化学习的协同作用,大语言模型在形式化数学证明和抽象推理任务中展现出超越传统监督微调的潜力。
技术实现层面,研究者构建了包含编码、模拟、强化学习与解码的完整架构。在编码阶段将问题转化为Gymnasium环境中的状态-动作空间,通过多维度游戏生成策略数据;解码阶段利用LLM对策略轨迹进行语义重构,最终结合上下文学习完成自动证明。该方法成功应用于2024年IMO组合题的实际求解,验证了其处理现实复杂问题的有效性。
原文和模型
【原文链接】 阅读原文 [ 1901字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章




