图解Transformer多头注意力机制
文章摘要
【关 键 词】 Transformer、多头注意力、自注意力、编码器、解码器
本文是关于Transformer架构中多头注意力机制的深入解析。多头注意力是Transformer模型的核心组成部分,它使得模型能够从多个角度理解数据,提升了信息处理的能力和效率。
多头注意力的工作原理
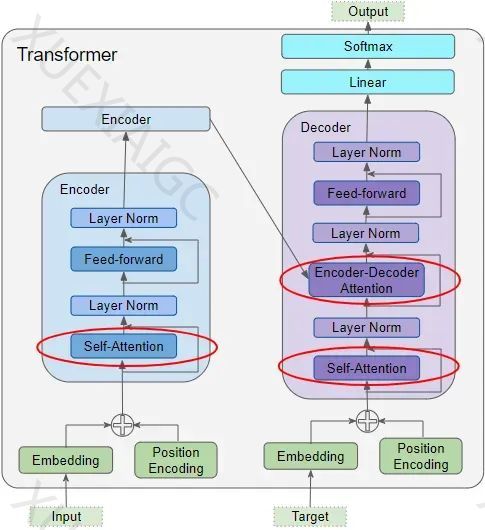
Transformer模型中的注意力机制包括三个主要部分:编码器的自注意力、解码器的自注意力以及编码器-解码器注意力。这些部分都使用了查询(Query)、键(Key)和值(Value)三个输入参数。编码器的自注意力使输入序列的每个元素都能关注到序列中的其他元素;解码器的自注意力则让目标序列的每个元素关注到目标序列中的其他元素;编码器-解码器注意力则是目标序列关注输入序列。
在多头注意力机制中,注意力模块将查询、键和值参数分成多个部分,每部分独立通过一个“注意力头”进行处理,然后将这些计算结果合并,形成最终的注意力得分。这种机制使得模型能够同时捕捉到不同的关系和细微差别。
注意力机制的关键超参数
多头注意力机制的关键超参数包括嵌入尺寸、查询尺寸(与键和值的尺寸相同)以及注意力头的数量。这些参数影响数据的维度和模型的性能。
多头注意力的计算过程
计算过程开始于输入层,其中输入嵌入和位置编码层生成一个矩阵,该矩阵随后被送入编码器的查询、键和值。接着,三个独立的线性层处理这些输入,生成Q、K和V矩阵。数据被分配到多个注意力头中,每个头独立处理数据。通过线性层的权重逻辑划分,可以完成这种分配。然后,Q、K和V矩阵被重塑,以包括一个明确的注意力头维度。
在每个头中,Q、K和V矩阵用于计算注意力得分。这个过程包括矩阵乘法、加入掩码值、缩放、应用Softmax函数,以及与V矩阵的另一次矩阵乘法。每个头的注意力得分随后被合并,通过调整矩阵的形状来消除头维度,最终形成一个统一的得分。
多头分割的意义
多头分割使得嵌入向量的不同部分可以学习单词的不同意义方面,尤其是它与序列中其他单词的关系。这种机制使得Transformer能够更丰富、更深入地解读序列。
解码器自注意力和掩蔽
解码器自注意力的工作原理与编码器自注意力类似,但它作用于目标序列的每个单词上。掩蔽机制用于屏蔽目标序列中的填充词,确保它们不参与注意力得分的计算。
编码器-解码器注意力和掩蔽
编码器-解码器注意力从两个不同的来源接收输入,计算每个目标词汇与每个输入词汇之间的相互作用。掩蔽机制在目标输出中遮蔽了后续的单词。
结论
文章希望通过对多头注意力机制的详细解释,帮助读者清晰地理解Transformer中注意力模块的作用。同时,文章也提出了关于注意力机制计算背后的原理和意义的问题,预告了系列文章的下一篇将会深入探讨这个话题。
原文和模型
【原文链接】 阅读原文 [ 3506字 | 15分钟 ]
【原文作者】 AI大模型实验室
【摘要模型】 gpt-4
【摘要评分】 ★★★★☆


相关文章


