文章摘要
【关 键 词】 语言模型、基准测试、多模态、AGI、智能助手
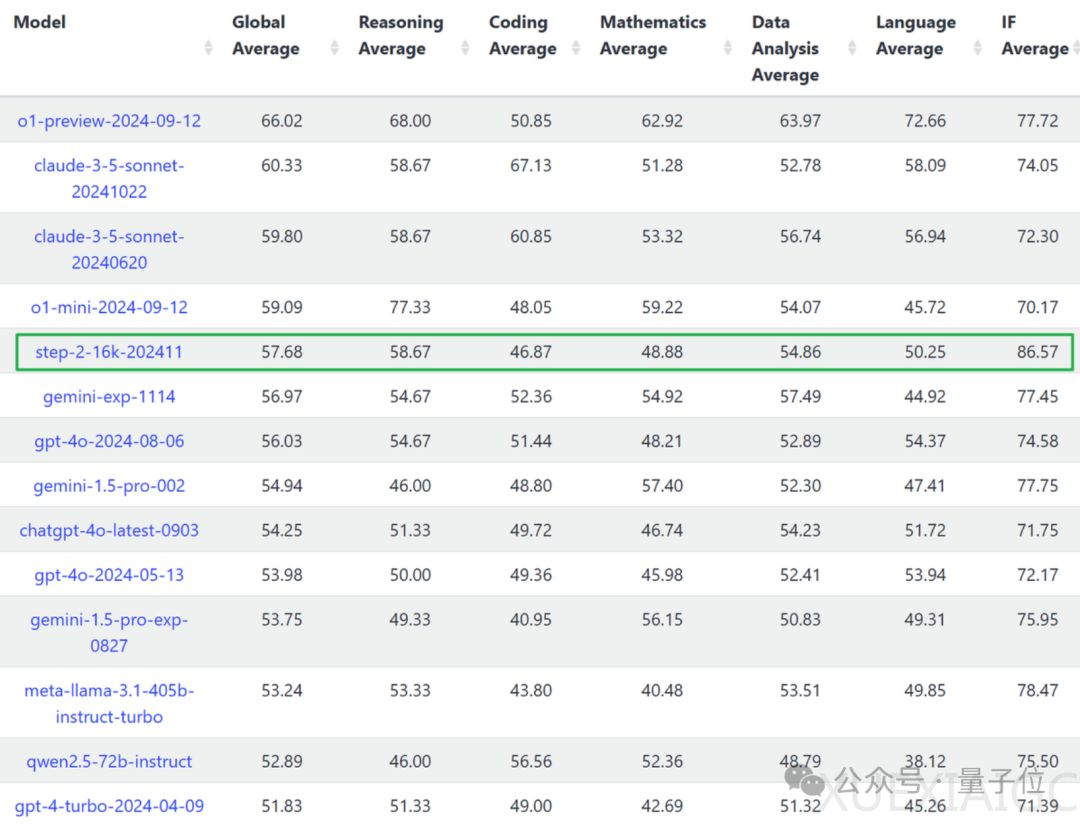
国内初创公司阶跃星辰的万亿参数语言大模型Step-2-16k-202411在LiveBench榜单上取得显著成绩,位列全球第五、国内第一。LiveBench是由图灵奖得主杨立昆联合纽约大学等机构推出的全球首个无法作弊的LLM基准测试,包含6个类别的17个不同任务,每月更新新问题,旨在确保评估的公平性和准确性。Step-2在指令跟随项目中以86.57分的成绩拿下全球第一,显示出其在语言生成上对细节的强控制力和理解能力。该模型采用MoE架构,完全自主研发,从头开始训练,通过部分专家共享参数、异构化专家设计等创新设计,使得每个专家都得到充分训练,总参数量达到万亿级别。此外,Step-2已接入阶跃星辰的C端智能生活助手“跃问”,并向开发者开放API接入使用。
阶跃星辰的Step系列除了语言模型外,还包括多模态模型Step-1.5V和图像生成大模型Step-1X。Step-1.5V在感知、推理和视频理解方面表现出色,而Step-1X则采用DiT架构,能够处理不同复杂度的文本指令和图像创意。阶跃星辰的目标是开发出能够实现AGI的多模态大模型,并利用这些自主研发的大模型创造新一代的AI应用。公司的研发迭代速度快,产品不局限于ChatBot,还推出了与iPhone 16和iOS18集成的新功能。
智源研究院推出的辩论平台FlagEval Debate通过模型辩论竞争机制为大模型能力评估提供新的度量标尺。Step-2在辩论中展现出强大的信息理解、知识整合、逻辑推理、语言生成和对话能力,最终在辩论中大胜o1。
原文和模型
【原文链接】 阅读原文 [ 2547字 | 11分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章


