文章摘要
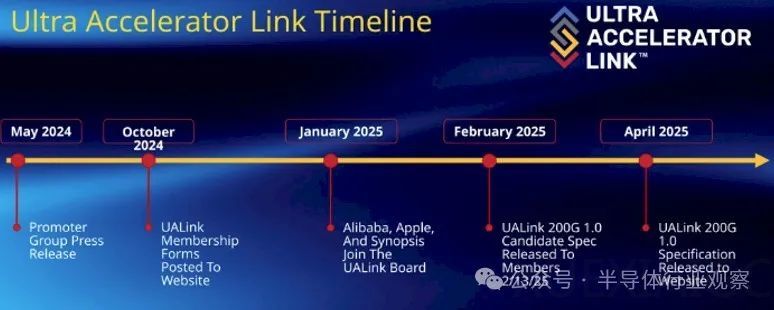
UALink 1.0 规范的发布标志着人工智能计算领域的一个重要里程碑。该规范由 UALink 联盟于 2024 年 5 月成立,成员包括 AMD、AWS、博通、思科、谷歌、HPE、英特尔、Meta、微软和 Astera Labs 等科技巨头。联盟的目标是提供一个开放的、替代 Nvidia NVLink 技术的标准,以支持大规模 AI 工作负载所需的联网 GPU 集群。UALink 1.0 规范支持 AI 计算舱内最多 1024 个加速器实现每通道 200G 的扩展连接,为下一代 AI 集群性能提供开放标准互连。
UALink 的主要优势包括高性能、低功耗、成本效益和开放性。它通过低延迟、高带宽的互连,为数百个加速器提供高效的通信支持。UALink 使用读取、写入和原子事务实现跨系统节点的加速器到加速器通信,并定义了一组协议和接口,从而为 AI 应用程序创建多节点系统。UALink 的功耗仅为同等以太网 ASIC 芯片面积的一半到三分之一,每个内存结构加速器可节省 150 瓦到 200 瓦的功耗。此外,UALink 的开放标准允许多家供应商开发兼容的加速器和交换机,推动行业创新和客户价值。
UALink 1.0 规范定义了一种用于加速器的高速、低延迟互连,支持每通道 200 GT/s 的最大双向数据速率。它可配置为 x1、x2 或 x4,四通道链路在发送和接收方向上均可实现高达 800 GT/s 的速度。UALink 电缆长度优化为 <4 米,在 64B/640B 有效载荷下实现 <1 µs 的往返延迟。这些链路支持跨一到四个机架的确定性性能。UALink 协议栈包括物理层、数据链路层、事务层和协议层,每一层都经过优化以提高性能和效率。
UALink 还支持集成的安全和管理功能,例如硬件级加密和身份验证,防止物理篡改,并通过租户控制的可信执行环境支持机密计算。UALink Pod 将通过专用控制软件和固件代理使用 PCIe 和以太网等标准接口进行管理,支持完全可管理性。UALink 的开放性和标准化使其成为未来 AI 基础设施的重要组成部分,预计将在十二到十八个月内投入使用,满足快速增长的市场需求。
总的来说,UALink 1.0 规范的发布为 AI 计算提供了一个开放、高效、低成本的互连解决方案,有望彻底改变云服务提供商、系统 OEM 和 IP/芯片提供商处理 AI 工作负载的方式。UALink 的推出标志着 AI 计算发展的重要一步,为未来的创新和应用奠定了坚实的基础。
原文和模型
【原文链接】 阅读原文 [ 3894字 | 16分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章




