华人研究团队揭秘:DeepSeek-R1-Zero或许并不存在「顿悟时刻」
文章摘要
【关 键 词】 自我反思、顿悟时刻、基础模型、响应长度、奖励设计
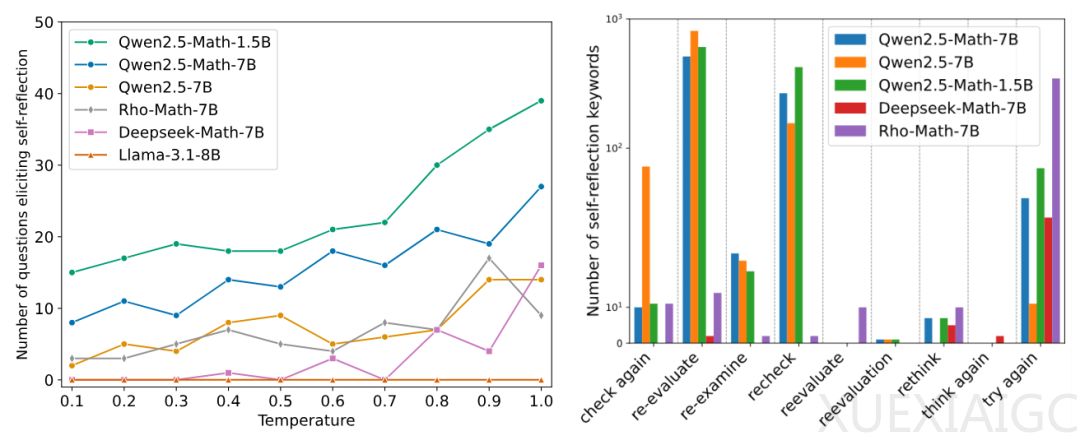
近期研究围绕类 R1-Zero 的训练展开,聚焦于模型自我反思能力及响应长度变化的机制。研究表明,“顿悟时刻”并非如以往所认为出现在强化学习(RL)训练后,而是在训练初始阶段(Epoch 0)已存在于基础模型中。通过对多种基础模型(如 Qwen-2.5、DeepSeek-Math 等)和提示模板的测试发现,这些模型在无后期训练的情况下即可表现出自我反思模式,关键词的出现频率随温度参数升高而增加。进一步验证表明,部分基础模型(如 Qwen2.5-Math)已具备一定的自我纠正能力,但这种能力往往表现为肤浅的自我反思(SSR),即缺乏建设性改进的重评估模式,甚至可能导致错误答案。
案例分析显示,基础模型的自我反思行为分为四种模式:确认正确答案、纠正错误、引入新错误以及反复无效反思。其中,后两种属于 SSR,说明基础模型虽能生成看似反思的内容,但难以保证推理结果的质量。通过对比正确与错误答案中的自我反思关键词频率,证实基础模型在高频率的自我反思中容易陷入肤浅反馈,未能显著提升解题准确率。
对于响应长度动态变化的研究指出,其激增现象主要由基于规则的奖励函数优化设计驱动,而非直接反映自我反思能力的增强。具体而言,RL 过程的早期通过抑制冗长的无效输出来优化奖励,在后期则鼓励更多尝试以获得更高奖励,导致响应长度增加。此外,响应长度与自我反思关键词数量并未呈现强相关性,表明长度变化无法作为自我反思能力的可靠指标。
综上所述,研究揭示了“顿悟时刻”的本质及其局限性,同时指出了自我反思质量的重要性,并强调了奖励设计对 RL 训练的影响。未来需更深入探讨如何有效优化模型的自我反思能力以实现高效推理。
原文和模型
【原文链接】 阅读原文 [ 2703字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen-max-2025-01-25
【摘要评分】 ★★★★☆


相关文章



