千页只需7块钱,Mistral发布世界最强文件扫描API,实测仍有缺陷
文章摘要
法国大模型独角兽 Mistral AI 近期推出了其光学字符识别(OCR)产品 Mistral OCR,号称是“世界上最好的 OCR 模型”。该模型以图像和 PDF 作为输入,能够以前所未有的准确度和认知能力理解文档的每个元素,包括媒体、文本、表格和公式。Mistral OCR 特别适用于处理多模式文档,如幻灯片或复杂 PDF,并已与 Le Chat 平台集成,供数百万用户免费试用。此外,Mistral AI 还发布了 API「mistral-ocr-latest」,价格为 1000 页/美元,目前已在开发者套件 la Plateforme 上提供,并计划向云和推理合作伙伴开放。
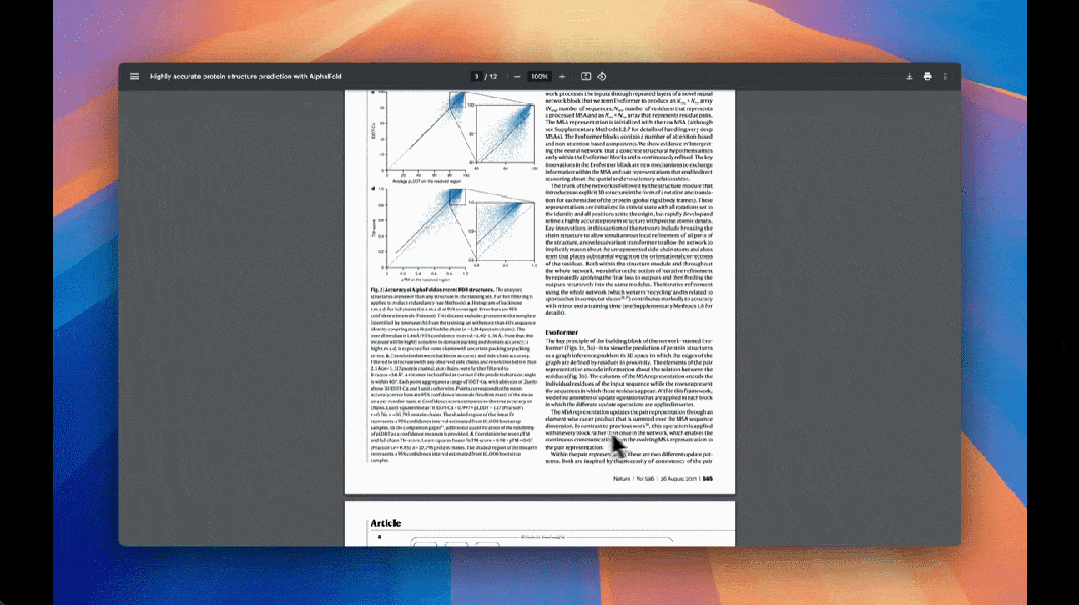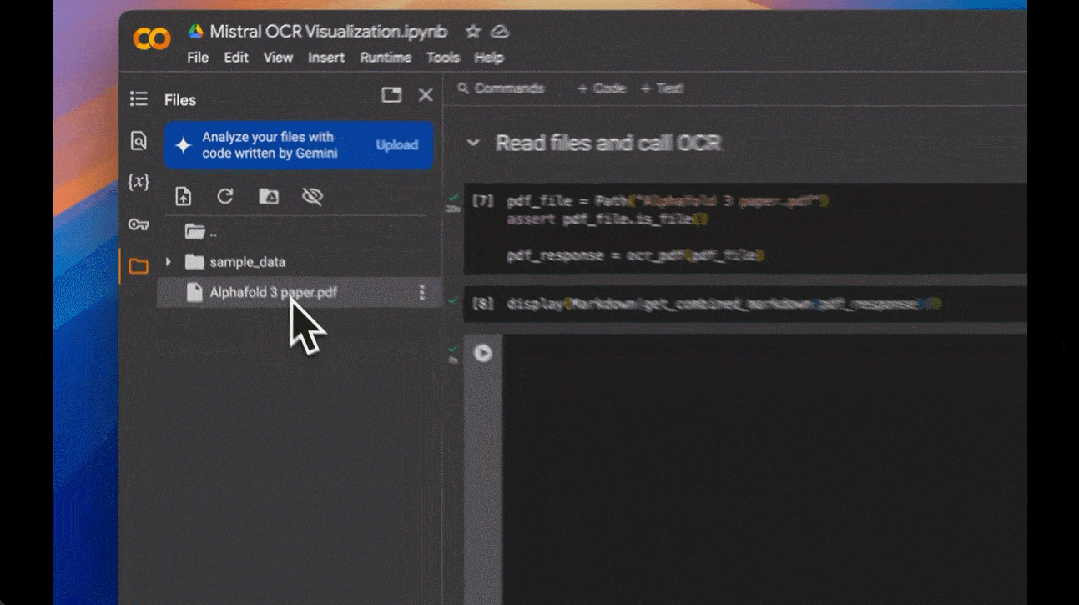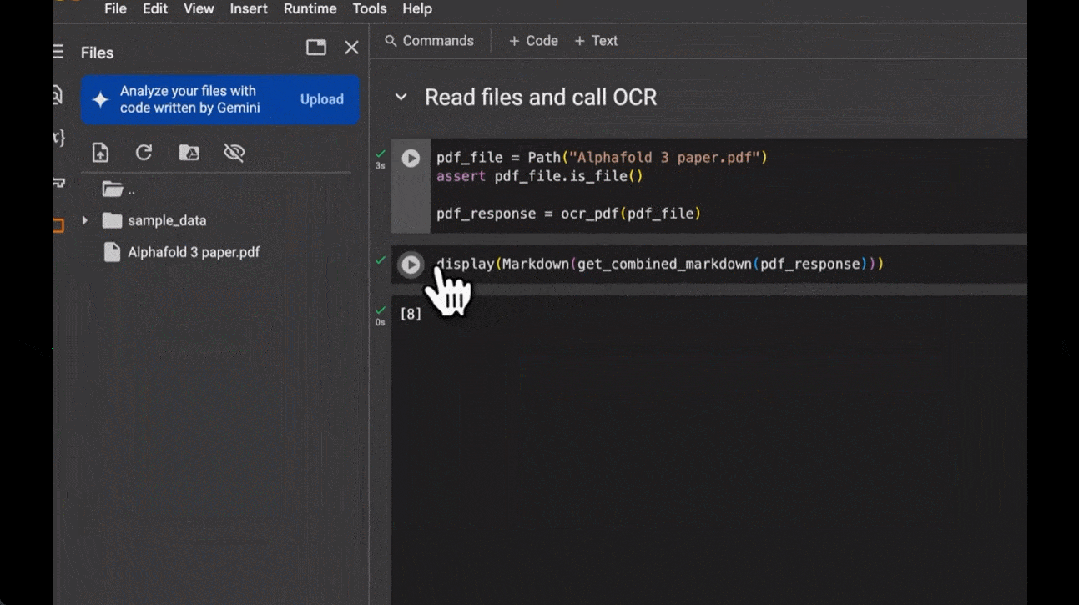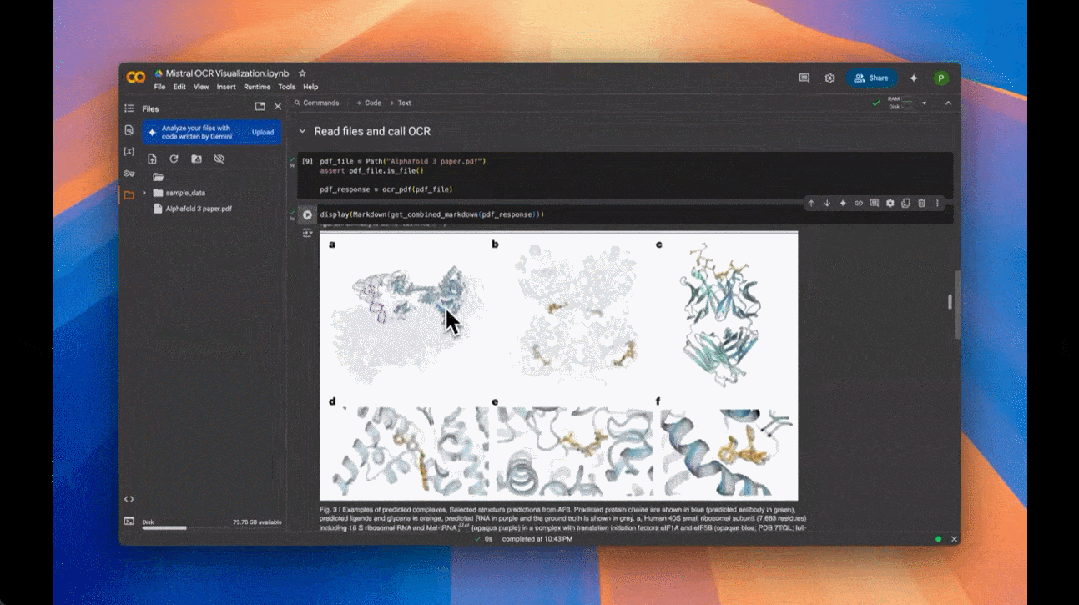
Mistral OCR 的核心优势在于其对复杂文档的深度理解能力。该模型能够处理交错图像、数学表达式、表格和高级布局(如 LaTeX 格式),尤其擅长解析科学论文中的图表、图形和公式。例如,在 Alphafold 3 的 OCR 识别测试中,Mistral OCR 成功将 PDF 中的文本和图像提取为 markdown 文档。此外,Mistral OCR 在严格的基准测试中表现优异,在文档分析的多个方面均优于其他领先的 OCR 模型。特别是在“仅文本”测试集和网络 PDF 上的性能测试中,Mistral OCR 展现了其卓越的文本和图像提取能力。
Mistral OCR 的另一大亮点是其对多语言的支持。该模型能够解析、理解和转录数千种脚本、字体和语言,适用于全球组织和小众市场的超本地化企业。在“Fuzzy Match in Generation”指标比较中,Mistral OCR 获得了第一,并在多种语言的测试中超越了 Azure OCR 和 Google Doc AI。此外,Mistral OCR 在速度上也表现出色,每分钟可处理 2000 多页文档,显著快于同类产品。
Mistral OCR 还引入了使用文档作为提示的功能,允许用户从文档中提取特定信息并将其格式化为结构化输出,如 JSON。这一功能为下游函数调用和智能体构建提供了便利。对于数据隐私要求严格的组织,Mistral OCR 提供了自行托管选项,确保敏感信息在组织内部的基础设施内保持安全。
尽管 Mistral OCR 在多个方面表现优异,但实际测试也揭示了一些局限性。在处理复杂的财务文档时,Mistral OCR 出现了列错位、精度偏差和丢失关键符号等问题。在法律文档的测试中,复选框检测和表格结构的处理也存在不足。Mistral AI 表示正在收集用户反馈,并计划在未来几周内进一步优化模型。
总体而言,Mistral OCR 在文档理解、多语言支持和处理速度方面展现了显著优势,但在处理复杂商业文档时仍需改进。随着模型的不断优化,Mistral OCR 有望在 OCR 领域树立新的标杆。
原文和模型
【原文链接】 阅读原文 [ 1598字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




