文章摘要
【关 键 词】 XRAG框架、RAG优化、模块化设计、性能评估、故障点管理
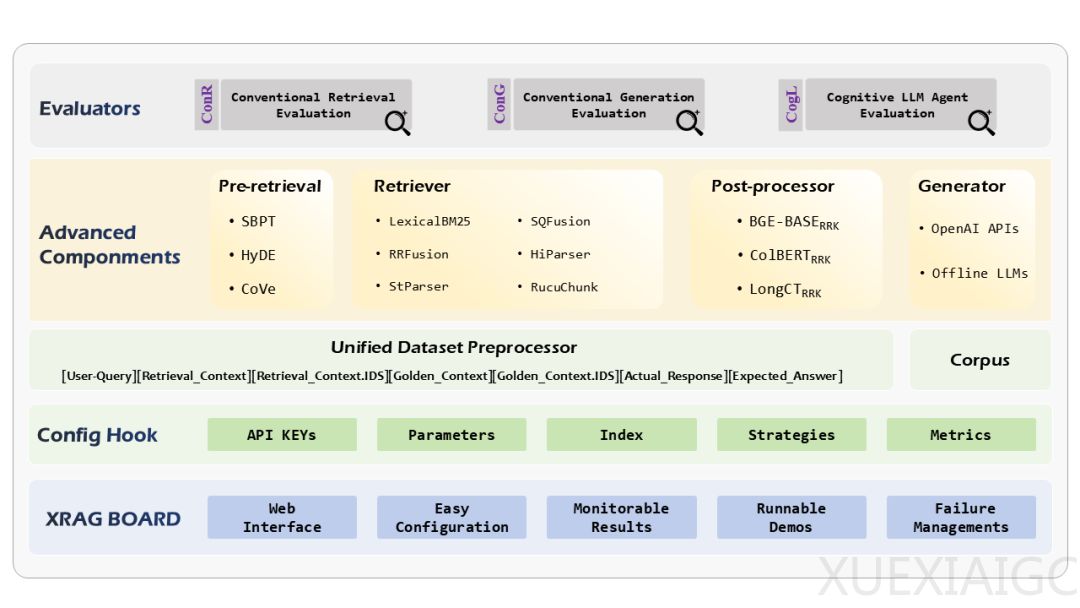
ZGCLAB与北航联合提出了XRAG,这是一个全面评测和优化增强生成RAG(Retrieval-Augmented Generation)的框架,包含50多个测试指标。XRAG支持4类高级RAG模块的对比,包括查询重构、先进检索、问答模型和后处理,并兼容OpenAI大模型API及本地化模型如Qwen和LlaMA。XRAG 1.0版本提供了简单的WebUI Demo,实现轻交互数据上传和统一标准格式,集成RAG失败点检测与优化方法。文章和代码已开源。
XRAG的核心功能包括模块化的RAG过程、统一基准数据集、全面的测试方法和识别优化RAG故障点。模块化RAG过程允许对高级模块进行实验分析,涵盖查询重写、高级检索、后处理技术和LLM生成器。XRAG标准化了三个流行的基准问答数据集,简化了不同RAG系统间的比较评估。全面的测试方法引入了一个多维度评估框架,包括传统检索评估、传统生成评估和基于LLM指令判别的评估,总计超过50个指标。XRAG还开发了一套失败点诊断的实验方法,以识别和纠正特定RAG问题,并提出针对性的改善策略与验证数据。
XRAG的优势在于其模块化设计、公平比较、统一数据集、模块评估、失败点管理和全面的指标。它将RAG过程划分为查询重写、高级检索、后处理、问答生成四个部分,提升了系统的灵活性与可扩展性。XRAG采用了统一的数据格式,便于对检索和生成模块进行性能测试,并选择了三个典型的数据集:HotpotQA、DropQA、NaturalQA,以突出多样性。
XRAG集成了检索测试的指标工具集,包括Jury、UpTrain和DeepEval,以及LlamaIndex中的指标,共计50个指标的测试性能。这些指标可以总结为一次性评估、标准化评估、字符级与语义级性能×检索与生成性能的优势。
实验结果表明,在三个数据集上的检索性能存在显著差异,最差的表现出现在DropQA数据集。RAG框架在NaturalQA数据集上表现出稳健的性能。从HotpotQA和DropQA数据集的角度来看,在回答过程中优化LLM的查询理解和推理能力具有明确的潜力。然而,大模型测试方法在三个数据集的结果可以发现,即使是基础的RAG系统,在使用LLM Agent做评估时,在检索和回答的成功率上表现出色,许多指标的得分均超过0.9。
XRAG系统故障点检测与优化方面,XRAG全面评估了其核心组件,并系统地识别了RAG流程中的多个潜在故障点,包括欺骗性响应、检索结果的不当排序、不完整的回答、对噪声的敏感以及处理复杂推理任务时的局限性等问题,并提出了针对性的常用优化方案。通过人工分析标准RAG流程下系统回复表现,筛选并构造了相应数据集,以实验验证优化方案的有效性。
原文和模型
【原文链接】 阅读原文 [ 3524字 | 15分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




