文章摘要
【关 键 词】 视频生成、AI技术、组合指令、动态稳定、开源代码
北京大学与快手AI团队合作提出了一个名为VideoTetris的新框架,旨在解决高难度、指令复杂的视频生成问题。该框架通过类似于拼图游戏俄罗斯方块的方式,轻松组合各种细节,生成复杂视频。在复杂视频生成任务中,VideoTetris超越了Pika、Gen-2等商用模型。
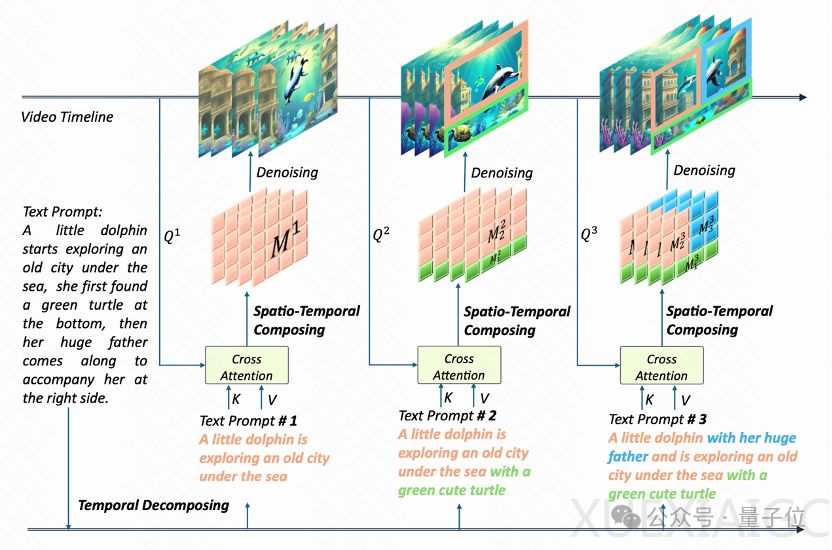
VideoTetris框架首次定义了组合视频生成任务,包括两个子任务:1) 跟随复杂组合指令的视频生成;2) 跟随递进的组合式多物体指令的长视频生成。目前,几乎所有开源模型和商用模型在生成正确视频方面都存在困难。例如,输入描述两个物体的指令时,现有模型往往生成融合了两个物体信息的奇怪视频。而VideoTetris能够成功保留所有位置信息和细节特征。
为了实现这一效果,VideoTetris采用了时空组合扩散方法。首先,将提示词按照时间解构,为不同视频帧指定不同的提示信息。然后,在每一帧上进行空间维度的解构,将不同物体对应不同的视频区域。最后,通过时空交叉注意力进行组合,实现高效的组合指令生成。此外,为了生成更高质量的长视频,团队还提出了一种增强的训练数据预处理方法,使长视频生成更加动态稳定。
VideoTetris还引入了一个参考帧注意力机制,使用原生VAE对之前的帧信息编码,区别于其他使用CLIP编码的方式。这样优化的结果是,长视频不再有大面积偏色现象,能够更好地适应复杂指令,生成的视频更具有动感,更符合自然。
为了评估组合生成的结果,团队引入了新的评测指标VBLIP-VQA和VUnidet,将组合生成评价方法首次扩展到视频维度。实验测试表明,在组合视频生成能力上,VideoTetris的表现超过了所有开源模型,甚至是商用模型如Gen-2和Pika。
据悉,VideoTetris的代码将完全开源。论文地址为:https://arxiv.org/abs/2406.04277,项目主页:https://videotetris.github.io/,GitHub地址:https://github.com/YangLing0818/VideoTetris。这一创新成果为高难度视频生成领域带来了突破性进展,有望推动相关技术的发展和应用。
原文和模型
【原文链接】 阅读原文 [ 1283字 | 6分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




