文章摘要
【关 键 词】 大模型、过度思考、推理效率、成本优化、评估框架
加州大学伯克利分校和苏黎世联邦理工学院等高校的研究人员深入探讨了大模型在执行Agent任务时面临的“过度思考”问题。过度思考是指大模型过度依赖内部推理,而忽视了从环境中获取或整合关键反馈的倾向。这种现象即使在资源不受限制的情况下,仍然会导致错误的累积和决策能力的下降。为了量化这种行为,研究人员开发了一套系统评估框架,并通过4018条轨迹分析发现,高推理努力配置的模型虽然解决了29.1%的问题,但成本高达1400美元;而低推理努力配置则以3.5倍更低的成本达到了21.0%的成功率。此外,生成两个低推理解决方案并选择其中一个具有较低过度思考得分的方法,实现了27.3%的解决率,同时减少了43%的计算成本。这表明减轻过度思考不仅提高了推理效率,还显著降低了成本。
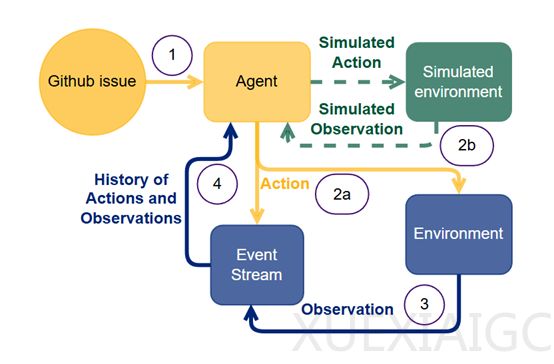
研究人员通过分析智能体与环境之间的交互过程,识别出三种过度思考的典型表现模式。首先是“分析瘫痪”(Analysis Paralysis),在这种情况下,模型过度专注于未来的规划,而忽视了当前环境中的实际进展。它们会生成越来越复杂的行动序列,但却难以系统地执行这些计划,从而陷入无休止的规划循环中。其次是“鲁莽行动”(Rogue Actions),在这种模式下,模型在面对错误时会尝试同时执行多个相互依赖的行动,而没有等待环境对前一个行动的反馈,模型试图用内部模拟来替代真实的环境反馈。最后是“过早脱离”(Premature Disengagement),在这种情况下,模型基于内部对问题空间的模拟而终止任务,而不是根据环境反馈来验证解决方案的有效性。这种过度依赖内部推理的行为可能导致模型在没有验证的情况下就放弃任务,或者错误地认为问题无法解决。
为了量化过度思考行为,研究团队开发了一种系统化的评分方法,使用大模型作为评判标准。该方法通过分析模型轨迹,识别出上述三种过度思考模式,并给出0到10分的评分,分数越高表示过度思考越严重。每个评分都附有详细的理由,解释所识别的模式及其严重程度。为了验证自动化评估方法的可靠性,研究人员邀请了四位专家手动评定了20个随机选择的模型轨迹。通过标准化评分,研究团队进行了全面的统计分析,探究过度思考行为与模型性能的关系,以及过度思考对推理模型和非推理模型的不同影响。结果显示,推理模型的过度思考得分显著高于非推理模型,且两者之间的相关性非常强,证实了自动评估方法的可靠性。
此外,研究团队设计了一个系统化评估轨迹的提示,避免使用“过度思考”一词以防止模型偏向自身定义。该提示围绕过度思考的三种表现形式展开,即分析瘫痪、鲁莽行为和过早脱离,并强调偏好内部推理链而非环境互动。评分系统分为三档:0-3分表示适当的环境互动,4-7分表示偶尔过度依赖内部推理,8-10分则表示完全脱离环境反馈。通过提供具体的例子,如模型得0分时会持续重试类似配置并在每次尝试间等待反馈,而得10分时会生成多个互依动作而不等待环境响应,或基于内部推理提前结束任务,确保评分标准的透明和一致。
实验结果表明,过度思考评分与任务解决率呈现出显著的负相关性。推理模型的过度思考评分越高,其在软件工程任务中的表现越差。这一趋势在非推理模型中也得到了体现,但其下降速度更快。例如,推理模型的趋势线斜率为-7.894,而非推理模型的趋势线斜率达到了-15.938。在模型类型与过度思考的关系方面,作者们发现推理模型的过度思考倾向明显高于非推理模型。实验数据显示,推理模型的平均过度思考评分为3.505,而非推理模型的平均评分为2.228。这种倾向可能是由于推理模型在训练过程中被优化为生成更长的推理链,从而在面对需要频繁与环境互动的任务时,表现出更高的过度思考倾向。此外,还研究了模型规模对过度思考的影响。实验结果表明,模型规模与过度思考评分之间存在负相关性。较小的模型,如7B和14B参数的模型在交互式任务中表现出更高的过度思考倾向,而较大的模型如671B参数的模型则相对较低。这一现象可能与模型的复杂性和对环境反馈的处理能力有关。
原文和模型
【原文链接】 阅读原文 [ 1527字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章




