刚刚,OpenAI放出最后大惊喜o3,高计算模式每任务花费数千美元
文章摘要
【关 键 词】 AI模型、推理能力、性能提升、安全测试、OpenAI
OpenAI最近发布了新的推理系列模型o3和o3-mini,作为o1系列模型的继任者,这些模型在回答问题前会花费更多时间进行思考以提高准确率。o3系列模型在ARC-AGI基准测试中表现出色,最低性能达到75.7%,而在更多计算资源的情况下,性能可提升至87.5%。ARC Prize Fundation总裁Greg Kamradt宣布o3是首个突破ARC-AGI基准的AI模型,该基准旨在通过基准测试指引实现人工通用智能(AGI)的道路。尽管o3在ARC-AGI上的表现接近人类水平,但Keras之父François Chollet指出o3并非AGI,因为它在一些简单任务上仍然失败,显示其与人类智能存在根本差异。
o3模型在编码能力上也有所提升,在SWE-bench Verified基准上的准确率约为71.7%,比o1模型高出20%以上。在竞赛数学和GPQA Diamond基准测试中,o3的准确率分别达到96.7%和87.7%,均优于o1模型。o3-mini作为o3的经济高效版本,专注于提升推理速度和降低成本,同时保持性能。它在Codeforces上的性能具有显著的成本效益,使其成为适合编程的模型。
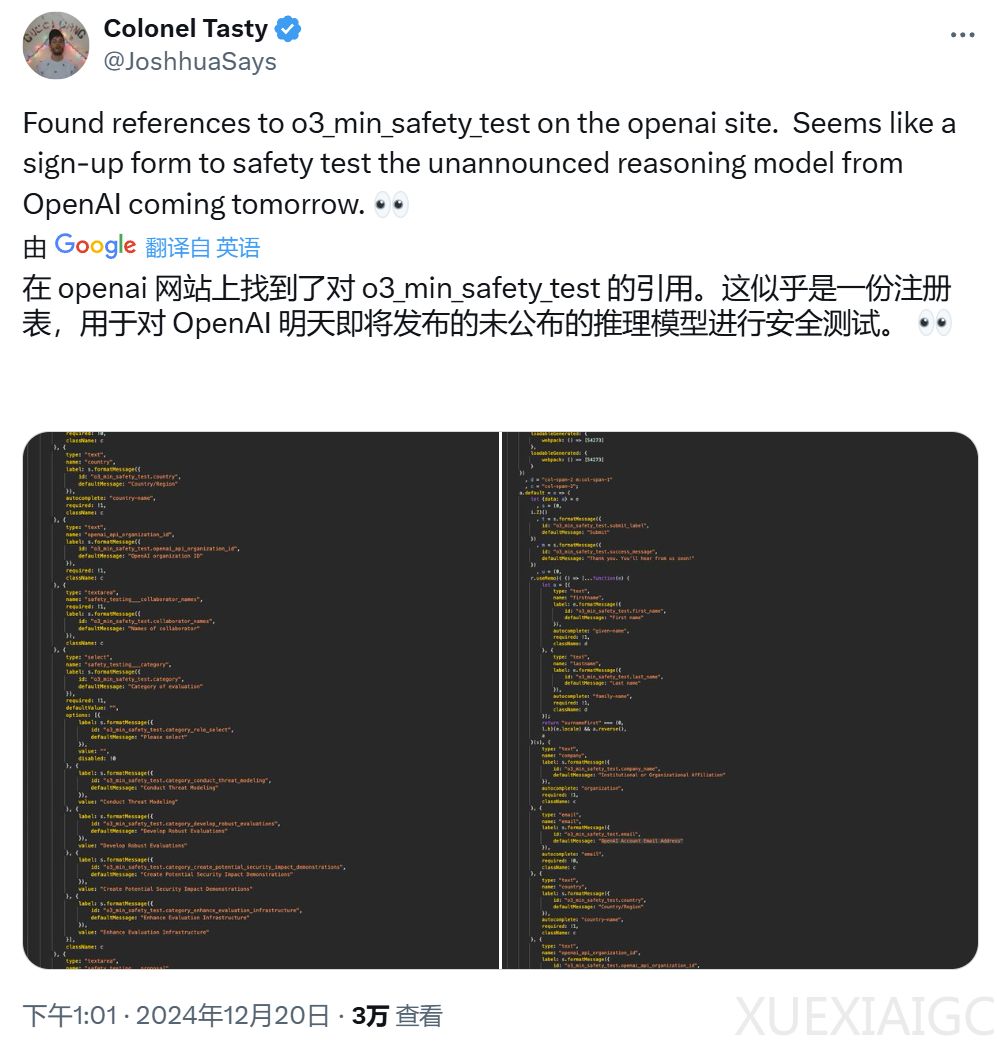
OpenAI正在进行o3和o3-mini的外部安全测试,并已开放早期访问申请。申请者需要提供相关信息,包括发表的论文链接和Github代码库,并选择希望测试的模型以及计划用途。OpenAI将滚动审核申请,并立即开始选拔申请人。此外,OpenAI介绍了一种新的安全评估方法——审议式对齐,这是一种直接教授模型安全规范的新范式,可以训练模型在回答前明确回忆规范并准确执行推理。
尽管o3模型在多个基准测试中表现出色,但关于其是否能解答最难的高考数学题,目前尚无确切答案。OpenAI的描述表明,o3在这些领域的表现是乐观的。
原文和模型
【原文链接】 阅读原文 [ 3038字 | 13分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章




