全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
文章摘要
【关 键 词】 语言模型、偏好优化、SimPO算法、奖励函数、性能评估
为使大型语言模型(LLM)与人类价值观和意图保持一致,学习人类反馈是关键。近期研究提出了一种简单有效的离线偏好优化算法——SimPO。
SimPO的核心优势在于其奖励函数与生成指标的对齐,消除了对参考模型的需求,简化了计算过程。
SimPO的关键设计包括:(1)长度归一化的奖励,计算方式为策略模型奖励中所有token的平均对数概率;(2)目标奖励差额,确保获胜和失败响应间的奖励差异超过该差额,增强分类器泛化能力。
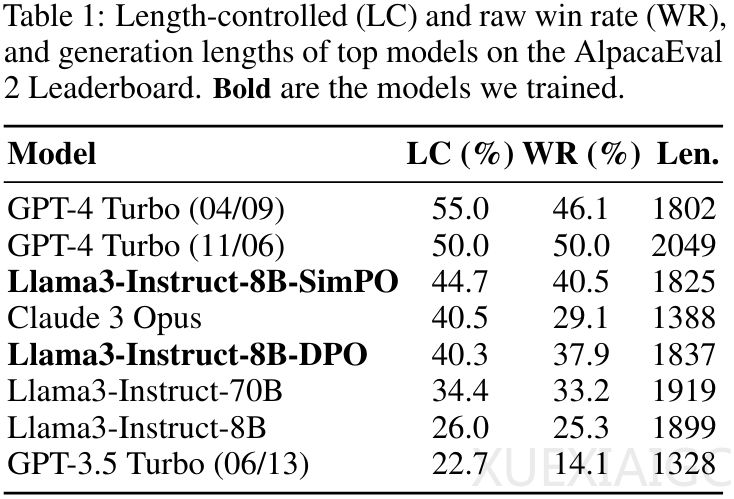
实验结果表明,SimPO在多样化对话能力评估基准上,如MT-Bench、AlpacaEval 2和Arena-Hard,显著优于其他偏好优化方法,展现了其在性能上的稳健性和有效性。
此外,研究指出,Instruct设置相比Base设置在所有基准上均有显著性能提升,暗示高质量SFT模型初始化和偏好数据的重要性。
消融实验进一步证明了SimPO设计中长度归一化和目标奖励差额的重要性。总之,SimPO为离线偏好优化提供了一种简单而强有力的新途径。
原文和模型
【原文链接】 阅读原文 [ 4298字 | 18分钟 ]
【原文作者】 机器之心
【摘要模型】 glm-4
【摘要评分】 ★★★★☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

