文章摘要
由UCLA等机构组成的研究团队在全球首次实现了在20亿参数的非监督微调模型上进行多模态推理的突破,这一成果被称为DeepSeek-R1的「啊哈时刻」。研究团队在未经监督微调的2B模型上,成功应用了DeepSeek-R1-Zero方法,展示了模型在多模态推理中的自我反思能力和回答长度的显著增加。这一突破表明,强化学习可以在没有任何监督推理数据的情况下,显著增强模型的推理能力。
研究团队从Qwen2-VL-2B基础模型出发,直接在SAT数据集上进行强化学习,避免了传统的监督微调(SFT)。通过这种方法,模型在CVBench基准测试上达到了59.47%的准确率,比基础模型高出约30%,比经过SFT的模型高出约2%。这一结果表明,视觉推理任务能够从强化学习中获益,并且展示了强化学习在多样化推理任务中的可扩展性。
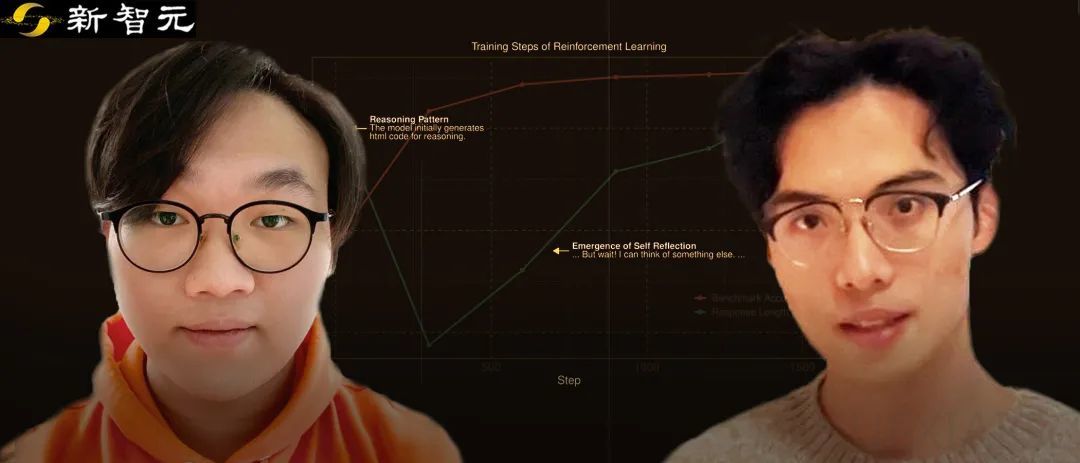
在研究过程中,团队观察到模型在训练初期回答长度下降,但通过强化学习,回答长度逐渐增加,并最终出现了多模态的「啊哈时刻」。这一现象表明,模型能够自主开发高级问题解决策略,并通过更长的思考时间提升推理能力。更长的推理过程对以视觉为中心的任务具有显著的益处,并且回答长度与基准准确率之间呈现出一致的正相关关系。
研究团队还发现,直接对未经监督微调的模型应用强化学习是实现「啊哈时刻」的关键。他们采用了GRPO算法,并使用基于规则的奖励函数,根据响应的格式和正确性进行评估。这种简洁的强化学习方法避免了复杂的奖励模型或蒙特卡洛树搜索技术,显著提高了模型的收敛速度。
此外,研究团队还进行了多项实验,探讨了不同微调设置对模型性能的影响。他们发现,尽管对指令微调模型应用强化学习可以提高性能,但这种方法并未复现DeepSeek-R1的关键特征,如回答长度的持续增长和自我反思能力的涌现。这表明,强化学习在视觉任务中的成功可能更多依赖于视觉处理能力的提升,而非推理能力的增强。
研究团队还探究了单纯奖励回答长度是否能提升模型性能,实验结果表明,单纯增加回答长度并不能有效提高模型的推理能力。模型会生成极长但无意义的回答,这表明需要设计更优的奖励机制来鼓励模型生成有意义的推理步骤。
未来,研究团队计划进一步分析多模态推理中响应长度的作用,并探索利用人工筛选的R1-Zero推理路径进行监督微调,以复现R1方法的效果。这一系列研究为AI社区提供了新的思路,展示了强化学习在多模态推理中的巨大潜力。
原文和模型
【原文链接】 阅读原文 [ 4230字 | 17分钟 ]
【原文作者】 新智元
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章




