全球首个多模态世界模型Emu3来了!智源王仲远:为多模态大模型训练范式指明新方向|钛媒体AGI
文章摘要
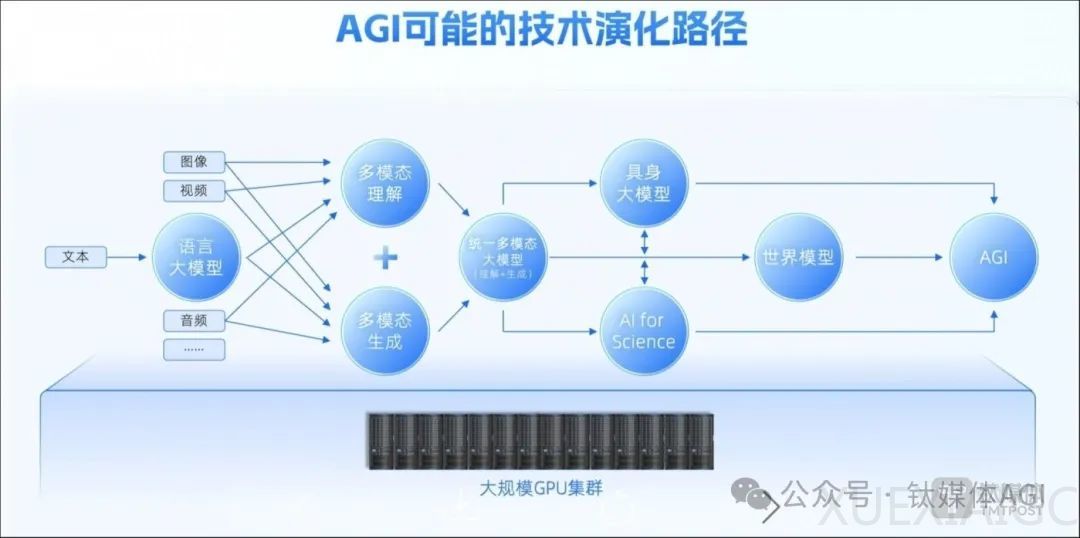
北京智源人工智能研究院(BAAI)近日发布了全球首个原生多模态世界模型Emu3,该模型采用了自回归技术路线,参数量达到8B(80亿),能够将图像、文本和视频编码为一个离散空间,并在多模态混合序列上从头开始联合训练一个Transformer模型。Emu3实现了视频、图像、文本三种模态的统一理解与生成,超越了传统模型单一类型的处理能力。在图像生成、视觉语言理解和视频生成任务中,Emu3的表现超过了国内外主流开源模型,如Stable Diffusion SDXL、LLaVA和OpenSora,展现了国际领先的AI技术。
智源研究院院长王仲远表示,Emu3证明了下一个token预测在多模态任务中的高性能表现,为构建多模态AGI提供了技术前景。Emu3的架构设计有利于产业化,未来将促进机器人大脑、自动驾驶、多模态对话和推理等场景的应用。王仲远强调,中国在大模型的技术路线上需要有自己的核心技术,Emu3能为多模态大模型训练范式指明新的方向。
智源研究院成立于2018年11月,是全球最早开展AI大模型的中国非营利性新型研究机构。研究院围绕大模型、类脑脉冲芯片、认知知识图谱等领先技术建立创新中心,推动AI原创成果转化及产业化。王仲远博士自2024年2月起担任院长,全面负责研究院工作。
Emu3所使用的自回归技术路线的核心思想是利用序列数据中的上下文依赖性来预测未来的数据点。该模型中不同模态数据共享同一套参数,可实现跨模态的关联和生成,无需人工设计的特征工程。然而,自回归技术路线在生成数据时模型必须按顺序进行,限制了并行计算的能力,导致生成速度较慢,也会遇到长期依赖问题。
尽管Emu3在多模态领域取得了显著进展,但仍存在挑战,如训练数据规模不够大、算力规模有限以及缺乏生态和实践者。王仲远表示,智源研究院需要更多资源,如扩大Emu3参数所需的算力和工程化能力,以及合作伙伴共同训练下一代模型。智源研究院将继续研发原生多模态世界模型Emu系列,解决更大规模的数据、算力以及训练问题,为整个行业指明方向。
原文和模型
【原文链接】 阅读原文 [ 3396字 | 14分钟 ]
【原文作者】 钛媒体AGI
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



