免费用!阿里通义大模型上新,超逼真音视频生成SOTA!
文章摘要
【关 键 词】 数字人、视频生成、语音合成、实时互动、多模态
阿里通义实验室推出的全新数字人视频生成大模型 OmniTalker,通过上传一段参考视频,能够学习并模仿视频中人物的表情、声音和说话风格。相比传统数字人生产流程,该方法显著降低了制作成本,提高了生成内容的真实感和互动体验,满足更广泛的应用需求。目前,该项目已在魔搭社区和HuggingFace开放体验入口,并提供了多个免费模板供用户使用。
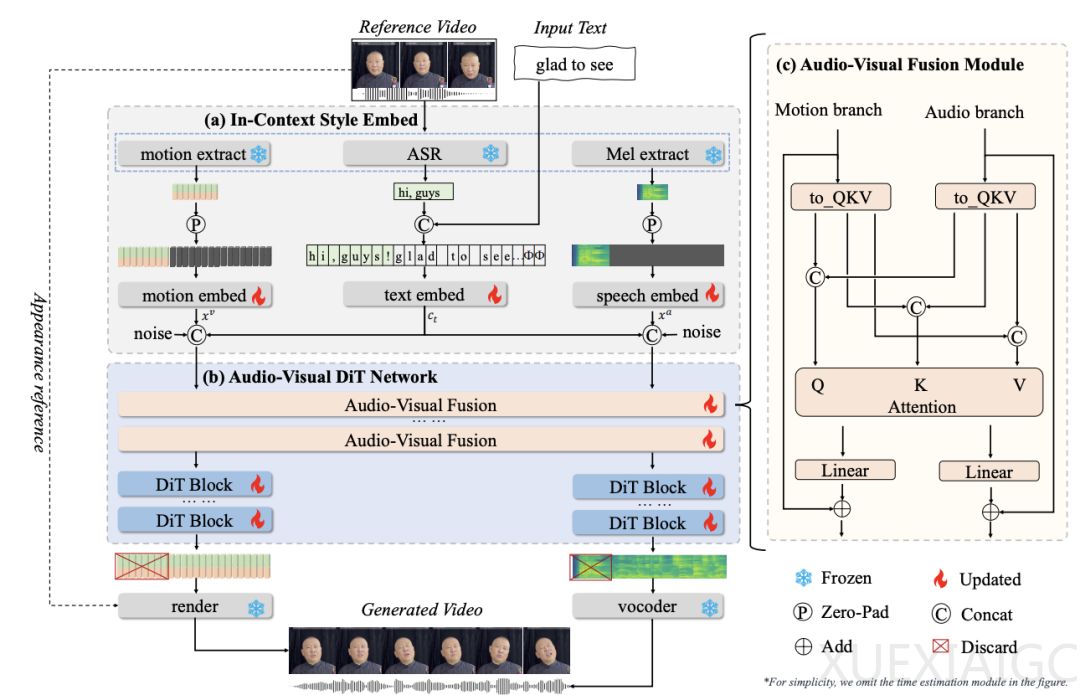
OmniTalker 的核心创新在于其端到端的统一框架,能够在零样本实时场景中,根据文本和参考视频同时生成同步的语音和数字人视频,同时保留语音风格和面部风格。该框架采用双分支 DiT 架构,音频分支从文本合成梅尔频谱图,视觉分支预测精细的头部姿态和面部动态。通过引入视听融合模块,OmniTalker 确保了音频和视觉输出在时间上的同步性和风格上的一致性。此外,上下文参考学习模块能够从单个参考视频中有效捕捉语音和面部风格特征,无需额外引入风格提取模块,从而优化了处理速度,确保了实时响应性能。
在模型结构方面,OmniTalker 通过三个嵌入模块分别捕捉参考音视频的动态特征以及文本信息,利用双流 DiT 模型进行音视频并行建模,并通过音视频特征融合模块确保音视频特征的紧密同步。训练阶段,音频和视觉特征会随机掩码序列的一部分,利用上下文学习来达成风格复刻的需求;推理阶段,则依据参考音频的节奏及输入文本的长度对音视频特征进行零填充,确保处理的一致性。
实验结果表明,OmniTalker 在音频生成和视频生成方面均表现出色。在文本转语音(TTS)技术评估中,OmniTalker 显示出更低的错词率(WER)和较高的声音相似度(SIM),证明了其在零样本条件下保持声音特征的能力。在音频驱动的数字人生成(THG)技术评估中,OmniTalker 在多个核心指标上达到业界领先水平,尤其在面部表情和头部姿势的真实感方面表现突出。通过引入新的评估标准 E-FID 和 P-FID,OmniTalker 在保持面部运动风格和头部姿态方面的能力得到了进一步验证。
OmniTalker 的实时性表现同样令人瞩目。通过采用 flow matching 技术和紧凑的模型架构,OmniTalker 实现了音视频的实时同步高质量输出,满足了实时应用的需求。这种能力使得 OmniTalker 在不牺牲输出质量的前提下,能够在实际应用中发挥重要作用。
阿里巴巴通义实验室的 HumanAIGC 团队在 2D 数字人和人物视频生成领域具有深厚的研究积累,已发表了多篇顶会论文。OmniTalker 的推出,进一步巩固了该团队在相关领域的技术领先地位,为数字人技术的未来发展提供了新的可能性。
原文和模型
【原文链接】 阅读原文 [ 3521字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章


