以加代乘?华为数学家出手,昇腾算子的高能设计与优化,性能提升30%!
文章摘要
【关 键 词】 大模型、推理优化、算子技术、硬件亲和、能效提升
随着大语言模型(LLM)参数规模的指数级增长,AI 的智力正在快速跃迁,但大模型在落地过程中面临着一系列推理层面的难题,如推理速度慢、计算成本高、部署效率低等问题。因此,大模型推理的「速度」与「能效」成为算力厂商与算法团队的核心命题。华为团队基于昇腾算力,发布了三项硬件亲和算子技术研究,旨在解决这些难题,并实现大模型推理速度与能效的双重突破。
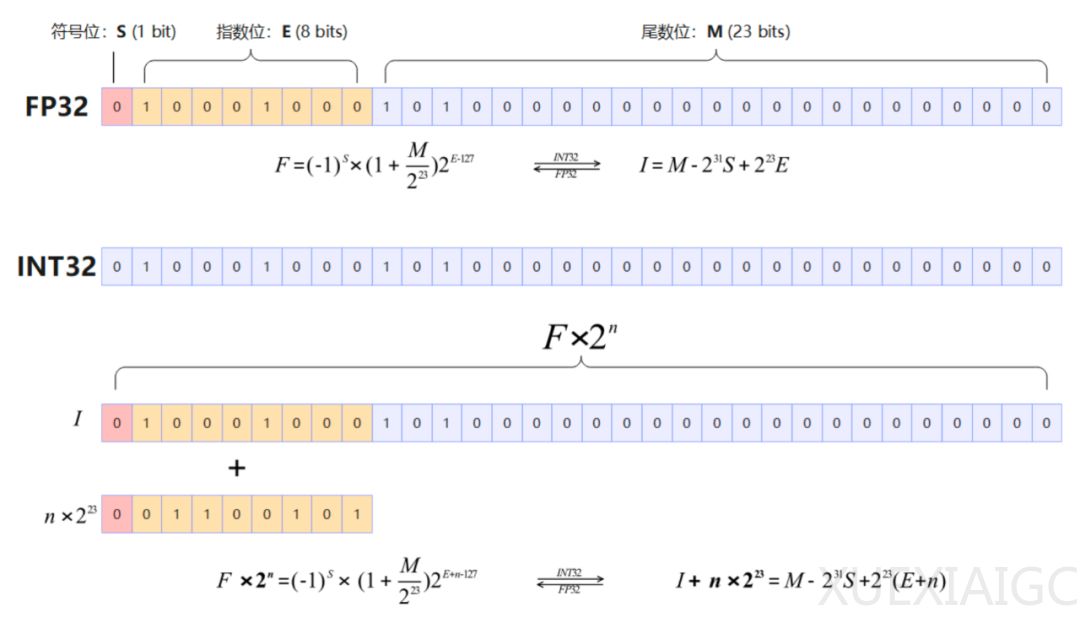
首先,华为提出了 AMLA(Ascend MLA)算子,通过数学等价变化和硬件亲和优化,将复杂的乘法运算转换为加法运算,充分利用存内算力,使算力利用率飙升至 71%。AMLA 算子的引入显著提升了 Attention 算子的性能,性能提升 30% 以上,算力利用率平均达到 55%,最高可达 71%。这一技术不仅减少了推理过程中的 KV Cache,还大幅降低了推理成本,为大模型的高效推理提供了重要支持。
其次,华为团队提出了融合算子优化技术,通过将多个算子合而为一,实现了计算、通信、存储的「三重协奏」。该技术利用昇腾芯片的多硬件单元并行能力,将跨硬件单元串行算子融合为复合算子,并通过指令级流水编排实现计算耗时的相互掩盖。此外,华为团队还通过数学等价关系解耦算子间数据依赖,重构计算顺序实现并行加速。这一技术体系在模型推理中实现了大幅性能提升,为大模型的部署提供了更高效的解决方案。
第三,华为推出了 SMTurbo 技术,通过昇腾原生 Load/Store 语义,实现了跨卡访存的超低延迟。SMTurbo 技术将 Load/Store 在读和写两个方向上并行,充分发挥了昇腾芯片读写分离的微架构优势,跨 384 卡的访存延迟低至亚微秒级。这一技术不仅提升了跨机访存通信的效率,还为稀疏模型推理提供了关键能力,进一步优化了大模型的推理性能。
未来,华为将继续深化这三类算子层面的优化技术。针对 AMLA,将研究仅 KV Cache 量化和全量化场景的 MLA 算子优化,扩展其应用场景;针对融合算子优化,将探索其在更多模型架构上的应用,推动大语言模型在昇腾硬件上的高效推理;针对 Load/Store 优化技术,将结合业务设计精巧的流水实现,平衡读写平面的负载分担,进一步提升大 BatchSize 下的实际收益。这些技术不仅将在昇腾生态中发挥关键价值,也有望为整个行业提供一个参考性范本。
在大模型架构日趋复杂、推理场景更加多样化的当下,算子层的优化正从单一性能突破迈向「数学创新、架构感知、硬件亲和」协同演进的全新阶段。华为的这三项技术为大模型推理的高效实现提供了重要支持,也为未来 AI 计算的发展指明了方向。
原文和模型
【原文链接】 阅读原文 [ 1851字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★☆


相关文章



