从LLM中完全消除矩阵乘法,效果出奇得好,10亿参数跑在FPGA上接近大脑功耗
文章摘要
【关 键 词】 深度学习、矩阵乘法、计算优化、模型性能、能源效率
在深度学习领域,矩阵乘法(MatMul)一直占据着核心地位,尤其是在语言模型中。然而,这一操作在计算开销和内存访问方面占据了很大比例。近期,来自加州大学圣克鲁兹分校等机构的研究者提出了一种全新的方法,成功从大规模语言模型中消除了MatMul操作,同时保持模型性能。
研究者指出,尽管GPU针对MatMul操作进行了优化,但它仍占据了训练和推理阶段的大部分执行时间和内存访问。为此,他们采用了两种策略:一是使用初等运算代替MatMul,例如在卷积神经网络中使用有符号加法;二是通过二值或三值化量化减少MatMul的复杂性。
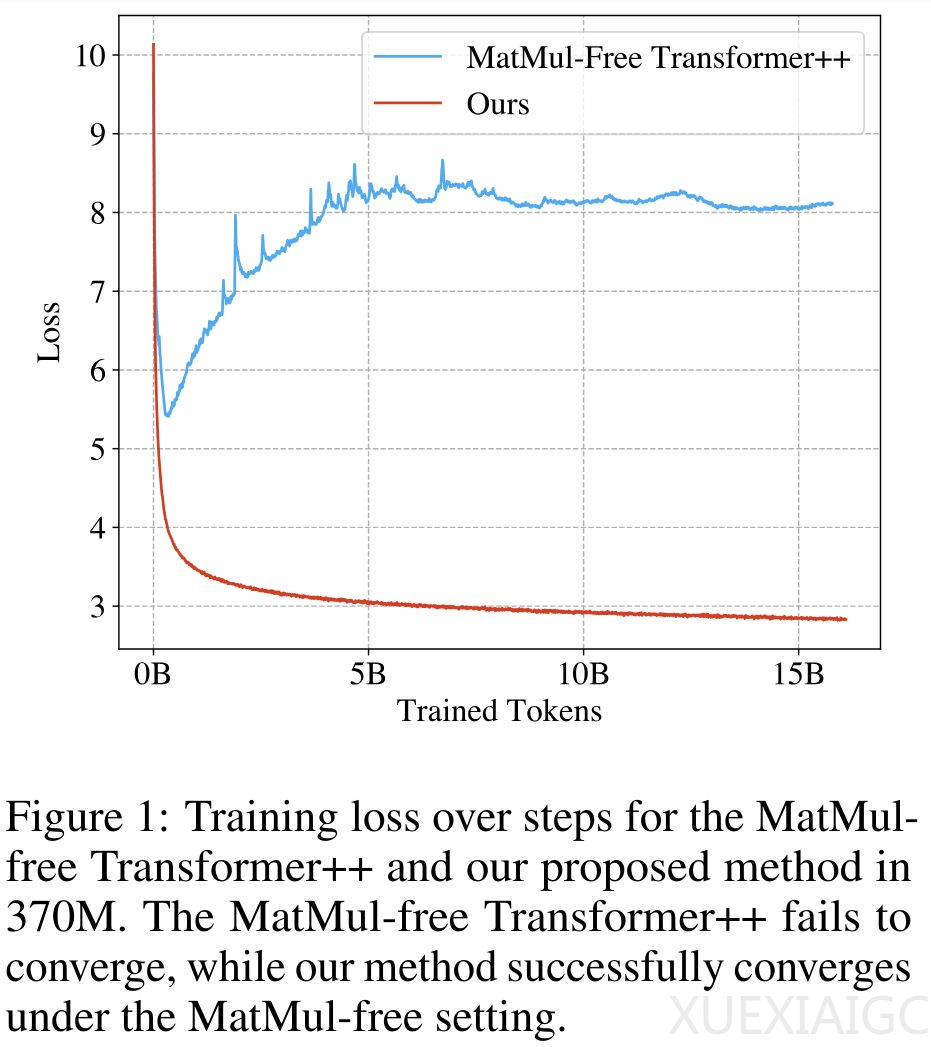
在这一研究中,研究者首次构建了可扩展的MatMul-free语言模型,通过在密集层中使用加法操作以及在自注意力类函数中使用元素级Hadamard乘积。他们采用三值权重消除了密集层中的MatMul,并在自注意力中优化了门控循环单元(GRU),使其仅依赖元素级乘积。实验结果表明,这种MatMul-free模型在性能上可媲美最先进的Transformer模型。
研究者在不同规模的模型上进行了测试,并发现随着模型规模的增加,MatMul-free模型与全精度Transformer之间的性能差距逐渐缩小。此外,他们还提供了一种高效的GPU模型实现,相比未优化的基线模型,在训练期间减少了多达61%的内存使用。
更有趣的是,研究者还在FPGA上构建了一个自定义硬件解决方案,以13W的功耗处理了十亿参数规模的模型,显示出极高的效率。然而,这种MatMul-free模型在大规模模型(如参数超过100B的模型)上的有效性仍有待观察。
这一研究不仅展示了消除MatMul操作的可行性,而且为语言模型的训练和部署提供了更高效、更节能的解决方案。随着模型的扩展,MatMul-free模型在利用额外计算资源提高性能方面表现出更高效的趋势,预计在极高计算规模下与传统的Transformer模型性能相当。这些发现为未来语言模型的发展提供了新的方向和启示。
原文和模型
【原文链接】 阅读原文 [ 3917字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 glm-4
【摘要评分】 ★★★★★


相关文章


