文章摘要
【关 键 词】 AWS云服务、Graviton 4、Arm服务器、Neoverse V2、性能测试
亚马逊网络服务(AWS)是云服务领域的领导者,也是Arm服务器技术的早期采用者。2018年,AWS推出了Graviton 1,采用16个Cortex A72内核。经过三代发展,Graviton 4搭载了96个Neoverse V2内核,后者是Arm Cortex X3的服务器版本,也是Arm Neoverse V系列的最新产品。Graviton 4的系统架构采用了Arm的CMN-700网格互连,配置了36MB共享L3缓存,内核间的缓存行反弹延迟在30-60纳秒之间。
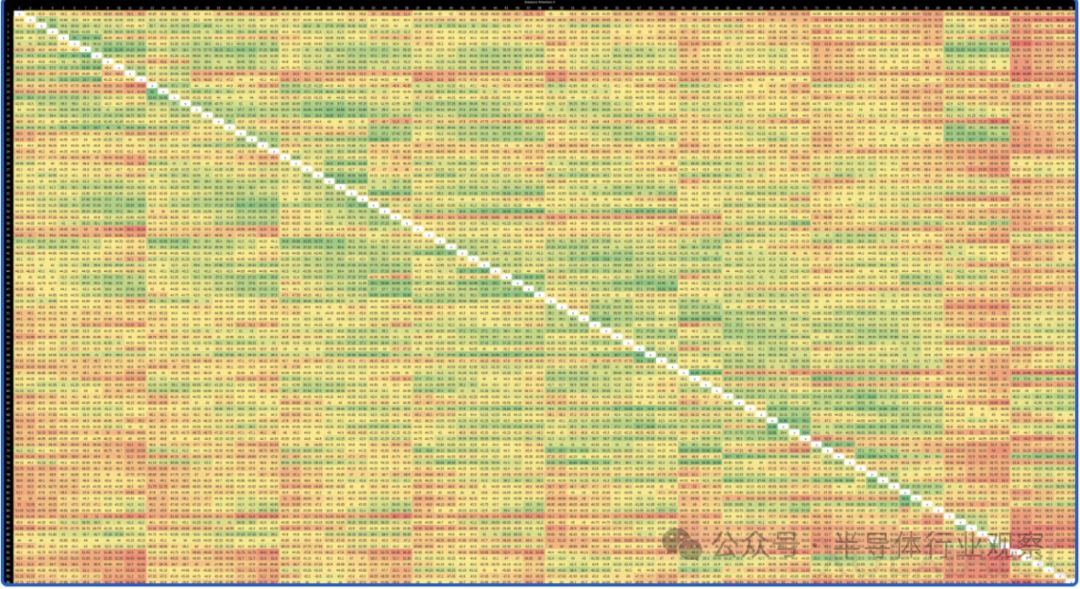
Graviton 4支持更大的实例,采用双插槽配置,提供192个内核和1536GB DDR5内存。在双插槽配置下,跨越插槽边界的延迟为138.6纳秒,与英特尔的Sapphire Rapids相似。Graviton 4在核心到核心延迟方面表现良好,与Graviton 2和3相当,同时提供了更多的内核数量。
Neoverse V2核心是Arm高性能核心系列的一部分,其宽度和重新排序能力与AMD的Zen 4相当。Graviton 4中的Neoverse V2运行速度高达2.8 GHz,双插槽实例的时钟速度降低到2.7 GHz。Neoverse V2使用了8组件TAGE预测器,表比Neoverse V1更大,减少了分支冲突的可能性。
在分支预测方面,Neoverse V2表现出色,与Golden Cove相似。然而,Zen 4可以处理更长的模式和更高的分支数。Neoverse V2的分支目标缓存采用三级BTB方案,能够处理非常大的分支足迹。Neoverse V2的返回堆栈有31个条目,处理调用+返回对的延迟与台式机Zen 4相当。
Neoverse V2的指令获取和解码阶段通过32项提取队列和64 KB L1指令缓存来提高性能。它还具有1536项微操作缓存,每周期可提供8个微操作。Neoverse V2的重命名和分配阶段每周期可以处理8个微操作,但测试结果显示实际为6个。Neoverse V2的执行引擎能够越过停滞的指令,保持执行单元的运行。
在整数和浮点/矢量执行方面,Neoverse V2具有6个ALU和四个128位管道,能够处理基本的FP和矢量整数运算。Neoverse V2的加载/存储单元包括三个地址生成单元(AGU),其中两个可以处理加载和存储,一个专用于加载。Neoverse V2的TLB设置为两级,L1 DTLB和L2 TLB。
Neoverse V2的L1数据缓存为64 KB,采用64B对齐,最小访问延迟为4个周期。L2缓存为1或2 MB,Graviton 4选择了2 MB选项,延迟为11个周期。Neoverse V2的L3带宽较低,单核的L3带宽为30 GB/s。
在基准测试中,Graviton 4在libx264编码4K视频和7-Zip压缩大型文件方面表现不一。Graviton 4在libx264中表现不佳,但在7-Zip中轻松击败了八核Bergamo CCX。Neoverse V2在两种工作负载下的平均IPC均高于Zen 4,但Zen 4的更高时钟频率和SMT能力使其具有优势。
总体而言,Graviton 4的双插槽配置在缓存一致性操作和DDR5设置方面表现出色,尽管跨插槽带宽和延迟有待提高。Neoverse V2核心在性能和效率方面取得了平衡,但在某些方面仍有提升空间。
原文和模型
【原文链接】 阅读原文 [ 6874字 | 28分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




